Autoencoder zur Anomalieerkennung
Rekonstruktionsbasierte Fehlerdetektion mit neuronalen Netzen
Was ist Anomalieerkennung mit Autoencodern?
Autoencoder sind neuronale Netze, die speziell dafür trainiert werden, normales Systemverhalten zu lernen und Abweichungen automatisch zu erkennen.
Typische Anwendungen sind:
- Überwachung von elektrischen Signalen
- Fehlererkennung in Hydrauliksystemen
- Condition Monitoring in Maschinen
- Cybersecurity (ungewöhnliches Verhalten erkennen)
Dieses Verfahren gehört zur unsupervised anomaly detection und wird häufig in Industrie, IoT und Machine Learning eingesetzt.
1. Motivation
In technischen Systemen - etwa bei elektrischen Signalen, Hydraulikanlagen oder Sensorüberwachung - stellt sich oft die Frage: Wie erkennt man Fehler, wenn keine expliziten Fehlermodelle vorhanden sind?
Eine elegante Lösung ist die rekonstruktionsbasierte Anomalieerkennung mit Autoencodern. Dabei wird ein neuronales Netz ausschliesslich mit Normalzuständen trainiert. Sobald ein unbekannter oder fehlerhafter Zustand auftritt, steigt der Rekonstruktionsfehler deutlich an.
- Unüberwacht (keine Fehlerlabels nötig)
- Modellfrei (keine physikalische Fehlerbeschreibung notwendig)
- Gut skalierbar auf viele Sensorsignale
2. Intuitive Erklärung
Ein Autoencoder lernt: "Wie sieht normales Systemverhalten aus?"
Bei bekanntem Zustand rekonstruiert das Netz gut. Bei unbekanntem Zustand (z. B. Sensorfehler, Drift, Defekt) kann das Signal nicht mehr sauber nachgebildet werden - der Fehler steigt.
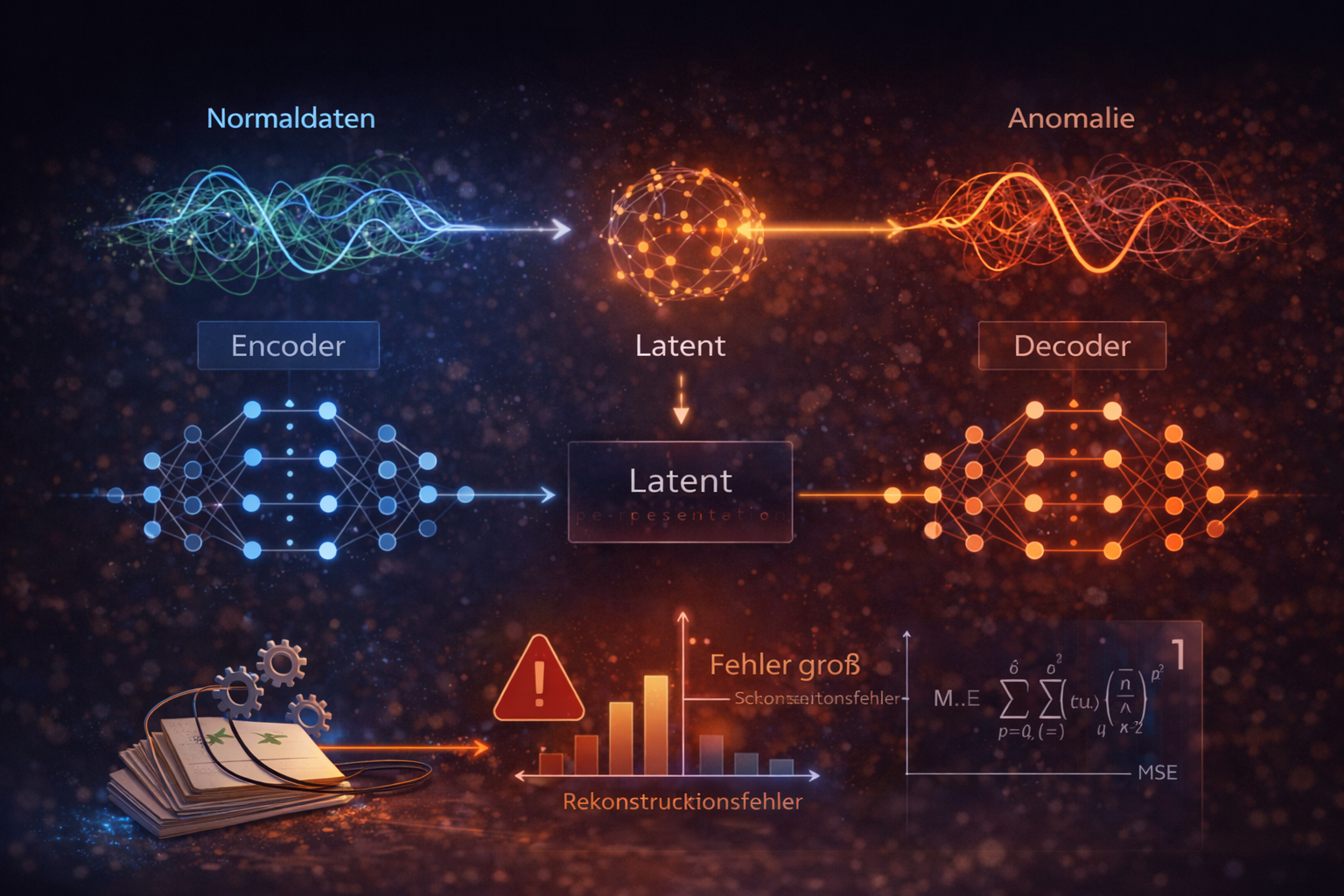
3. Grundprinzip eines Autoencoders
Ein Autoencoder besteht aus drei Teilen:
Eingang \(x\) -> Encoder -> Latenter Raum \(z\) -> Decoder -> Rekonstruktion \(\hat{x}\)
Encoder: Komprimiert das Eingangssignal, \(z = f(x)\).
Latenter Raum: Verdichtete Repräsentation der wichtigsten Merkmale.
Decoder: Rekonstruiert das Eingangssignal, \(\hat{x} = g(z)\).
Fehlerberechnung: Typisch ist der Mean Squared Error (MSE):
\[\mathrm{Loss} = ||x - \hat{x}||^2\]
Ist der Fehler grösser als ein definierter Schwellenwert, wird der Zustand als Anomalie markiert.
Der Autoencoder approximiert eine Funktion: \[ \hat{x} = g(f(x)) \] wobei \(f\) der Encoder und \(g\) der Decoder ist.
Das Ziel ist: \[ \min ||x - g(f(x))||^2 \]
Der latente Raum wirkt dabei als Informationsflaschenhals, der nur die wichtigsten Strukturen des Signals durchlässt.
Der latente Raum kann als Projektion auf eine niedrigdimensionale Mannigfaltigkeit verstanden werden. Normale Daten liegen nahe dieser Struktur, während Anomalien ausserhalb liegen.
4. Kleines Rechenbeispiel
Wir betrachten ein vereinfachtes 2D-Sensorsystem \(x = (x_1, x_2)\) mit Normalannahme \(x_2 \approx x_1\).
Linearer Mini-Autoencoder:
\[ z = 0.5x_1 + 0.5x_2,\quad \hat{x}_1 = z,\quad \hat{x}_2 = z \]
Normalfall: \(x = (2, 2.1)\)
\[ z = 2.05,\quad \hat{x} = (2.05, 2.05),\quad e = (-0.05, 0.05),\quad \mathrm{MSE} \approx 0.005 \]
Sehr klein -> normaler Zustand.
Fehlerfall: \(x = (2, 5)\)
\[ z = 3.5,\quad \hat{x} = (3.5, 3.5),\quad e = (-1.5, 1.5),\quad \mathrm{MSE} = 4.5 \]
Deutlich höher -> Anomalie.
5. Anwendung in der Praxis (Signalüberwachung)
In technischen Systemen, wie z. B. der Überwachung von Sensoren oder elektrischen Signalen, kann ein Autoencoder kontinuierlich den Normalzustand lernen.
Typische Fehler, die erkannt werden:
- Sensor-Drift
- Rauschen ausserhalb des normalen Bereichs
- plötzliche Signaländerungen
- Hardwaredefekte
6. Implementierung in Python (PyTorch)
Das folgende Minimalbeispiel trainiert einen Autoencoder nur auf Normaldaten und vergleicht danach den Fehler für Normal- und Fehlerprobe.
import torch
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(0)
# 1) Trainingsdaten (Normalzustand): x2 ~ x1 + kleines Rauschen
n_samples = 1000
x1 = torch.randn(n_samples, 1)
x2 = x1 + 0.1 * torch.randn(n_samples, 1)
data = torch.cat((x1, x2), dim=1)
# 2) Autoencoder
class Autoencoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(2, 4),
nn.ReLU(),
nn.Linear(4, 1)
)
self.decoder = nn.Sequential(
nn.Linear(1, 4),
nn.ReLU(),
nn.Linear(4, 2)
)
def forward(self, x):
z = self.encoder(x)
x_hat = self.decoder(z)
return x_hat
model = Autoencoder()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 3) Training
for _ in range(200):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, data)
loss.backward()
optimizer.step()
# 4) Test: Normalzustand vs. Fehlerzustand
normal_sample = torch.tensor([[2.0, 2.1]])
anomaly_sample = torch.tensor([[2.0, 5.0]])
error_normal = criterion(model(normal_sample), normal_sample)
error_anomaly = criterion(model(anomaly_sample), anomaly_sample)
print("Normal Error:", error_normal.item())
print("Anomaly Error:", error_anomaly.item())7. Schwellenwertbestimmung
Die Wahl des Schwellenwerts ist entscheidend: Ein zu niedriger Wert führt zu vielen Fehlalarmen, ein zu hoher Wert übersieht echte Fehler.
In der Praxis wird der Threshold oft anhand von Validierungsdaten optimiert.
\[ \mathrm{Threshold} = \mu + 3\sigma \]
Alle Fehlerwerte darüber werden als Anomalie eingestuft.
8. Autoencoder in der Praxis: Training in Python, Ausführung auf der SPS
In realen Automatisierungssystemen wird ein Autoencoder in der Regel nicht direkt auf der SPS trainiert. Das Training erfolgt offline in Python, zum Beispiel mit PyTorch. Dort stehen Optimierungsverfahren wie Backpropagation und Adam sowie grosse Trainingsdatensätze zur Verfügung.
Nach dem Training werden nur die erlernten Modellparameter übernommen:
- Encoder-Gewichte und Bias-Werte
- Decoder-Gewichte und Bias-Werte
- die gewählte Aktivierungsfunktion
Auf der SPS läuft anschliessend nur die Inferenz. Das bedeutet: Der aktuelle Merkmalsvektor wird durch den Encoder und Decoder geführt, das Signal rekonstruiert und der Rekonstruktionsfehler als Anomalie-Mass berechnet.
Dieses Vorgehen ist besonders interessant für industrielle Anwendungen, weil die SPS nur wenige Rechenoperationen ausführen muss und dennoch ein trainiertes neuronales Modell nutzen kann.
FUNCTION_BLOCK Autoencoder_5_3_5
VAR_INPUT
enable : BOOL;
(* Feature-Vektor *)
x1 : REAL;
x2 : REAL;
x3 : REAL;
x4 : REAL;
x5 : REAL;
threshold : REAL := 0.05;
END_VAR
VAR_OUTPUT
valid : BOOL;
anomaly : BOOL;
mse : REAL;
h1 : REAL; h2 : REAL; h3 : REAL;
x1_hat : REAL;
x2_hat : REAL;
x3_hat : REAL;
x4_hat : REAL;
x5_hat : REAL;
END_VAR
VAR
x : ARRAY[0..4] OF REAL;
h : ARRAY[0..2] OF REAL;
x_hat : ARRAY[0..4] OF REAL;
z : REAL;
err : REAL;
i, j : INT;
END_VAR
(* Initialisierung *)
valid := FALSE;
anomaly := FALSE;
mse := 0.0;
IF enable THEN
x[0] := x1;
x[1] := x2;
x[2] := x3;
x[3] := x4;
x[4] := x5;
(* ENCODER *)
FOR j := 0 TO 2 DO
z := 0.0;
FOR i := 0 TO 4 DO
z := z + x[i];
END_FOR
h[j] := TANH(z);
END_FOR
(* DECODER *)
FOR i := 0 TO 4 DO
z := 0.0;
FOR j := 0 TO 2 DO
z := z + h[j];
END_FOR
x_hat[i] := z;
END_FOR
(* Fehlerberechnung *)
err := 0.0;
FOR i := 0 TO 4 DO
err := err + (x[i] - x_hat[i]) * (x[i] - x_hat[i]);
END_FOR
mse := err / 5.0;
anomaly := (mse > threshold);
valid := TRUE;
END_IF
Struktur des Structured-Text-Beispiels
- Eingänge: fünf normalisierte Merkmale aus dem Prozess
- Encoder: lineare Kombination mit anschliessender tanh-Aktivierung
- Latenter Raum: kompakte Darstellung in drei Variablen
- Decoder: Rekonstruktion des ursprünglichen Merkmalsvektors
- Fehleranalyse: Berechnung des mittleren quadratischen Fehlers (MSE)
- Entscheidung: Vergleich mit einem Schwellwert zur Anomalieerkennung
9. Vorteile und Grenzen
Vorteile:
- Keine Fehlermodelle notwendig
- Erkennt unbekannte Fehler
- Geeignet für hochdimensionale Sensordaten
- Unüberwachtes Lernen
Grenzen:
- Schwellenwertwahl ist kritisch
- Repräsentative Normaldaten sind entscheidend
- Drift kann die Erkennungsqualität verschlechtern
10. Fazit
Die Anomalieerkennung mit Autoencodern ist ein leistungsfähiger und flexibel einsetzbarer Ansatz für technische Systeme. Die Kernidee lautet: Kompression -> Rekonstruktion -> Fehleranalyse.
Gerade bei vielen Sensorsignalen lassen sich komplexe Zusammenhänge modellieren, ohne explizite Fehlerklassen definieren zu müssen.
Autor: Ruedi von Kryentech
Erstellt am: 06.04.2026 · Zuletzt aktualisiert: 06.04.2026
Fachlicher Stand zum Zeitpunkt der letzten Aktualisierung.