Fehlerkorrekturcodes in biometrischen Authentifizierungssystemen
Wie verrauschte biometrische Messungen für sichere Schlüssel nutzbar werden
Interaktiv ausprobieren: Mit dem Hamming Code Rechner kannst du Datenbits kodieren, Bitfehler simulieren und sehen, wie das Syndrom die fehlerhafte Position findet.
Einleitung
Während meines Studiums als Elektroingenieur habe ich Fehlerkorrektur ursprünglich im Kontext von Kommunikationssystemen kennengelernt – also zur Korrektur von fehlerhaft übertragenen Nachrichten.
In meinem eigenen Projekt VisuKey wurde mir jedoch schnell klar, dass sich diese Konzepte auch auf reale Messdaten übertragen lassen. Besonders interessant ist dabei der Einsatz in biometrischen Authentifizierungssystemen.
Dazu gehören unter anderem:
- Fingerabdruck-Erkennung
- Gesichtserkennung
- Iris-Scanner
- bildbasierte Authentifizierung
Ein zentrales Problem solcher Systeme ist die natürliche Variabilität der Daten. Zwei Messungen derselben Person sind niemals exakt identisch.
Genau hier kommen Fehlerkorrekturcodes ins Spiel: Sie ermöglichen es, diese Unterschiede auszugleichen und stabile, reproduzierbare Authentifizierungsinformationen zu erzeugen.
Das Problem verrauschter Daten
Biometrische Daten enthalten immer ein gewisses Mass an Rauschen.
Wenn ein Bild zweimal aufgenommen wird, entstehen Unterschiede durch:
- Beleuchtung
- Kamerarauschen
- Perspektive
- Bildkompression
Das resultierende Datenmuster ist ähnlich, aber nicht identisch.
Fehlerkorrekturcodes
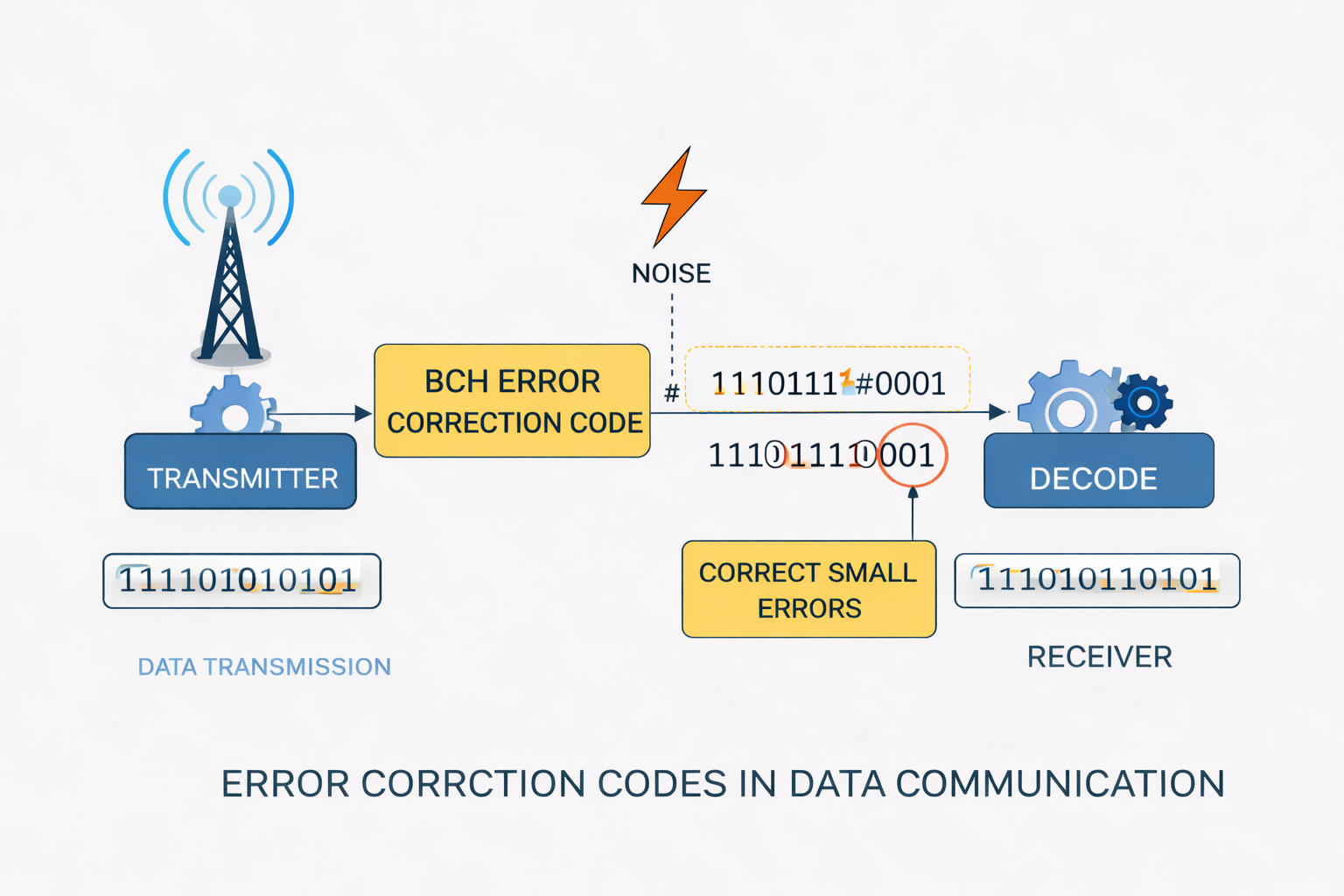
Fehlerkorrekturcodes wurden ursprünglich für Kommunikationssysteme entwickelt. Ihr Zweck besteht darin, Bitfehler zu erkennen und zu korrigieren.
Ein Sender kodiert Daten mit zusätzlichen Redundanzbits. Der Empfänger kann dadurch Fehler erkennen und korrigieren.
Repetitionscodes – Einstieg in die Fehlerkorrektur
Ein einfacher, aber sehr anschaulicher Fehlerkorrekturcode ist der Repetitionscode. Dabei wird jedes Bit mehrfach übertragen, um Übertragungsfehler ausgleichen zu können.
Beim 3-fachen Repetitionscode gilt:
0 → 000
1 → 111
Die Entscheidung erfolgt über Majority Voting. Formal kann man sagen, dass der empfangene Vektor r auf das nächste gültige Codewort abgebildet wird.
Die Menge der gültigen Codewörter ist:
C = {000, 111}
Die minimale Hamming-Distanz beträgt:
d = 3
Damit kann genau ein Fehler korrigiert werden, da gilt:
t = ⌊(d - 1) / 2⌋ = 1
Generatormatrix – systematische Konstruktion von Codes
Während Repetitionscodes intuitiv verständlich sind, werden moderne Codes über Matrizen beschrieben. Die Generatormatrix G definiert dabei die Abbildung von Informationsbits auf Codewörter.
Allgemein gilt:
t = s · G
mit:
- s ∈ {0,1}k – Nachrichtenvektor
- G ∈ {0,1}k×n – Generatormatrix
- t ∈ {0,1}n – Codewort
Alle Operationen erfolgen in GF(2), also modulo 2 (XOR statt Addition).
Systematische Form der Generatormatrix
In vielen praktischen Codes wird die Generatormatrix in systematischer Form dargestellt:
G = [ Ik | P ]
mit:
- Ik – Einheitsmatrix (Originaldaten bleiben erhalten)
- P – Paritätsmatrix
Das bedeutet: Die ersten k Bits im Codewort sind die Originaldaten, die restlichen Bits sind Redundanz.
Beispiel: (7,4)-Hamming-Code
Die Generatormatrix lautet:
G =
[ 1 0 0 0 | 1 1 0 ]
[ 0 1 0 0 | 1 0 1 ]
[ 0 0 1 0 | 0 1 1 ]
[ 0 0 0 1 | 1 1 1 ]
Hier ist klar erkennbar:
- links: Identität (Datenbits)
- rechts: Paritätsstruktur
Beispielrechnung:
s = (1 0 1 0)
Berechnung (Modulo-2):
t = s · G =
(1·Zeile1) ⊕ (0·Zeile2) ⊕ (1·Zeile3) ⊕ (0·Zeile4)
t = (1 0 0 0 1 1 0) ⊕ (0 0 1 0 0 1 1)
t = (1 0 1 0 1 0 1)
Parity-Check-Matrix – Struktur der Fehlererkennung
Die Parity-Check-Matrix H beschreibt die Nebenbedingungen, die jedes gültige Codewort erfüllen muss.
Für ein gültiges Codewort gilt:
H · tT = 0
Das bedeutet: Jedes Codewort liegt im Nullraum von H.
Aufbau der Parity-Check-Matrix
Für systematische Codes gilt:
H = [ PT | In-k ]
Das ist genau die Struktur, die du auch in deinen Abbildungen siehst.
Beispiel (7,4)-Hamming-Code:
H =
[ 1 1 0 | 1 0 0 0 ]
[ 1 0 1 | 0 1 0 0 ]
[ 0 1 1 | 0 0 1 0 ]
Syndrom und Fehlerlokalisierung
Beim Empfang eines Wortes r wird das Syndrom berechnet:
z = H · rT
- z = 0 → kein Fehler
- z ≠ 0 → Fehler vorhanden
Das Entscheidende: Jede Spalte von H entspricht einem Bit im Codewort.
Das Syndrom zeigt direkt auf die Spalte – und damit auf das fehlerhafte Bit.
Beispiel
Empfangen:
r = (1 0 1 0 1 0 0)
Berechnung:
z = H · rT = (0 1 0)
→ entspricht Spalte 2 → Bit 2 ist falsch → wird invertiert
Geometrische Interpretation
Man kann Codewörter als Punkte im n-dimensionalen Raum betrachten. Fehler verschieben den Punkt leicht.
Die Decodierung entspricht der Projektion auf das nächste gültige Codewort im Sinne der Hamming-Distanz.
Übertragung auf VisuKey und biometrische Daten
Im Anwendungsfall VisuKey entstehen binäre Vektoren aus biometrischen Embeddings.
Diese Vektoren sind jedoch nicht stabil – kleine Änderungen führen zu Bitfehlern.
Die Matrizenstruktur hilft hier entscheidend:
- G definiert die stabile Codierung
- H prüft Konsistenz und erkennt Fehler
- das Syndrom ermöglicht gezielte Korrektur
Damit wird ein verrauschtes biometrisches Signal auf einen stabilen Code abgebildet – die Grundlage für reproduzierbare kryptographische Schlüssel.
Anwendung von Fehlerkorrekturcodes in biometrischen Systemen
In biometrischen Systemen werden sogenannte Embeddings verwendet. Dabei handelt es sich um hochdimensionale Vektoren, die ein biometrisches Merkmal – beispielsweise ein Gesicht – numerisch beschreiben.
Ein typisches Embedding liegt im kontinuierlichen Raum (z. B. ℝn). Für kryptographische Anwendungen muss dieses jedoch in einen stabilen binären Vektor überführt werden:
x ∈ ℝn → b ∈ {0,1}n
Diese Binarisierung ist kritisch, da kleine Änderungen im Eingangssignal (z. B. Beleuchtung oder Pose) zu Bitflips führen können.
Formal kann man das empfangene Signal als gestörte Version betrachten:
r = b ⊕ e
mit:
- b – idealer binärer Vektor
- e – Fehlervektor (Rauschen)
Die Aufgabe des Fehlerkorrekturcodes besteht darin, aus r wieder das ursprüngliche b zu rekonstruieren.
Stabilitätsanalyse und Bit-Selektion
Ein entscheidender Schritt ist die Auswahl stabiler Bits. Nicht alle Bits eines Embeddings sind gleich zuverlässig.
Für jedes Bit i kann eine Stabilitätsmetrik definiert werden, z. B. über wiederholte Messungen:
pi = P(bi stabil)
Typische Verfahren:
- Varianzanalyse über mehrere Aufnahmen
- Signal-to-Noise Ratio (SNR)
- Hamming-Distanz zwischen Wiederholungen
Nur Bits mit hoher Stabilität werden weiterverwendet:
bstable = Auswahl(b, pi > Schwelle)
Dadurch reduziert sich die effektive Fehlerrate erheblich und die Anforderungen an den Fehlerkorrekturcode werden geringer.
Fuzzy Extractor – Verbindung von Biometrie und Kryptographie
In modernen Systemen wird häufig das Konzept des Fuzzy Extractors verwendet.
Die Idee: Aus verrauschten biometrischen Daten wird ein stabiler kryptographischer Schlüssel erzeugt.
Der Prozess besteht aus zwei Phasen:
- Enrollment:
b → (w, helper data) - Rekonstruktion:
r + helper data → b → Schlüssel
Die helper data enthalten Informationen aus dem Fehlerkorrekturcode, ohne den Schlüssel selbst preiszugeben.
Typischerweise gilt:
w = Hash(b)
und der Fehlerkorrekturcode stellt sicher, dass trotz Rauschen immer dasselbe b rekonstruiert wird.
Welche Fehlerkorrekturcodes sind für VisuKey geeignet?
Die Wahl des Codes hängt stark von der Fehlerrate und Struktur der Daten ab.
1. Hamming-Codes
- sehr effizient (geringe Redundanz)
- korrigieren nur 1 Bitfehler
- geeignet für sehr stabile Daten
→ Für biometrische Systeme meist zu schwach.
2. BCH-Codes (in VisuKey verwendet)
- korrigieren mehrere Bitfehler (t einstellbar)
- flexible Parameter (n, k, t)
- gut analysiert und effizient implementierbar
Ein BCH-Code erfüllt:
dmin ≥ 2t + 1
→ kann t Fehler sicher korrigieren
Typisches Beispiel:
- (255, 131, t=15)
→ geeignet für moderate Rauschlevel in Embeddings
3. LDPC-Codes
- sehr leistungsfähig bei hoher Fehlerrate
- iterative Decodierung
- höherer Implementierungsaufwand
→ interessant für zukünftige Versionen mit stärkerem Rauschen
4. Reed-Solomon Codes
- arbeiten auf Symbolen statt Bits
- robust gegenüber Burst-Fehlern
→ weniger geeignet für binarisierte Embeddings
Warum BCH-Codes für VisuKey besonders geeignet sind
In VisuKey entstehen Fehler typischerweise als verteilte Bitflips durch kleine Änderungen im Bild.
Die Eigenschaften von BCH-Codes passen gut dazu:
- Fehler sind zufällig verteilt → BCH optimal
- Fehlerrate moderat → kein LDPC nötig
- deterministische Decodierung → stabiler Output
Zusätzlich lassen sich BCH-Codes gut mit Bit-Selektion kombinieren:
effektive Fehlerrate ↓ → kleinere t ausreichend
Kombinierter Ablauf in VisuKey
- Bild aufnehmen
- Embedding berechnen (z. B. 512-dim)
- Binarisierung → b
- Stabile Bits auswählen → bstable
- BCH-Codierung anwenden
- Helper Data speichern
- Schlüssel ableiten (Hash)
Bei erneutem Einlesen:
- neues r entsteht
- Fehlerkorrektur rekonstruiert b
- identischer Schlüssel wird erzeugt
Fazit
Fehlerkorrekturcodes sind die zentrale Komponente, um verrauschte biometrische Daten in stabile kryptographische Schlüssel zu überführen.
Besonders BCH-Codes bieten dabei einen optimalen Kompromiss aus Effizienz, Fehlerkorrekturfähigkeit und Implementierbarkeit.
Die Kombination aus Signalverarbeitung, statistischer Bit-Selektion und Codierungstheorie ermöglicht es, aus unscharfen realen Messdaten eine zuverlässige und sichere Authentifizierung zu erzeugen – wie im Fall von VisuKey.
Autor: Ruedi von Kryentech
Erstellt am: 06.04.2026 · Zuletzt aktualisiert: 06.04.2026
Fachlicher Stand zum Zeitpunkt der letzten Aktualisierung.