Wie funktioniert ChatGPT?
Large Language Models – einfach erklärt & technisch tief analysiert
ChatGPT, GPT-4, Gemini und andere LLMs – vom nächsten Wort bis zum Transformer: kompakte Einordnung und technischer Unterbau
1. Was ist ein Large Language Model (LLM)?
Kurzfassung: Ein LLM ist ein grosses tiefes neuronales Netzwerk, das Token-Wahrscheinlichkeiten über Kontext lernt und daraus Texte erzeugt.
Ein Large Language Model (LLM) ist ein mathematisches Modell, das darauf spezialisiert ist, Sprache zu verarbeiten und zu generieren. Im Kern handelt es sich nicht um „Verstehen“ im menschlichen Sinn, sondern um ein Wahrscheinlichkeitsmodell über Text.
Das bedeutet konkret: Ein LLM berechnet für jedes mögliche nächste Wort (oder genauer gesagt: Token) die Wahrscheinlichkeit, mit der es am besten zum bisherigen Text passt.
LLM = tiefes neuronales Netzwerk
Wichtig ist: Ein LLM ist nicht etwas völlig anderes als ein neuronales Netzwerk, sondern selbst ein grosses tiefes neuronales Netzwerk. „Tief“ bedeutet dabei, dass viele Schichten hintereinander geschaltet sind, die den Eingabetext Schritt für Schritt transformieren.
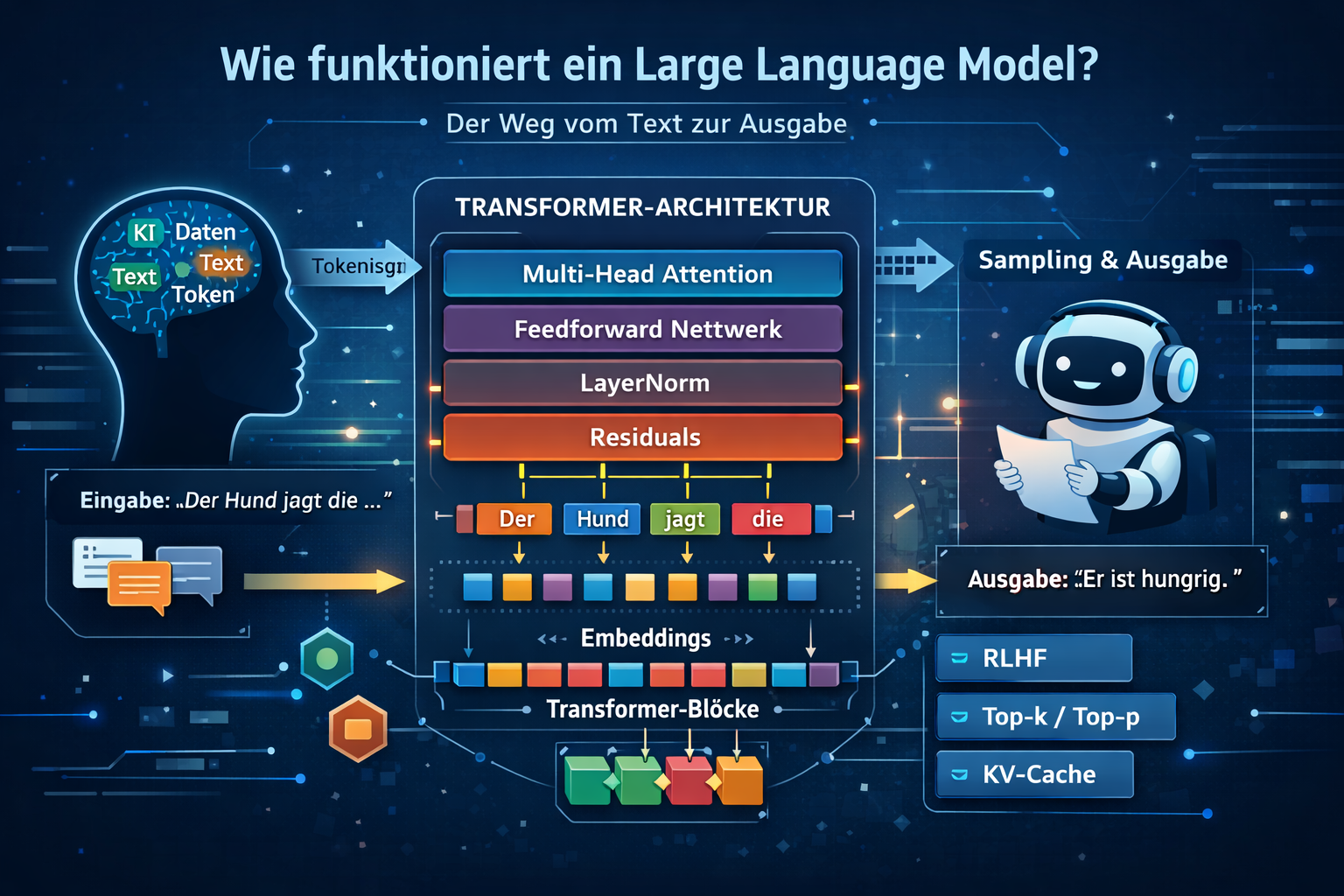
Moderne LLMs basieren fast immer auf der Transformer-Architektur. Diese besteht aus wiederholten Blöcken aus Attention, Feed-Forward-Netzwerken, Residual-Verbindungen und Layer Normalization. Die Gewichte dieser Blöcke werden während des Trainings so angepasst, dass die Vorhersage des nächsten Tokens immer besser wird.
Was bedeutet „neuronales Netzwerk“ hier konkret?
Ein neuronales Netzwerk ist im Kern eine grosse Funktion mit vielen trainierbaren Parametern. Aus einem Eingabesignal \(x\) wird über viele gewichtete Transformationen eine Ausgabe \(y\):
\[ y = f_{\theta}(x) \]
Bei einem LLM ist das Eingabesignal kein Bild oder Messwert, sondern eine Folge von Tokens. Das Netz wandelt diese Tokens zuerst in Vektoren um und verarbeitet sie dann durch viele Schichten, bis am Ende eine Wahrscheinlichkeitsverteilung über das nächste Token entsteht.
Warum „deep learning“?
Ein einfaches neuronales Netz mit nur einer oder zwei Schichten könnte die Komplexität natürlicher Sprache nicht gut erfassen. Erst durch viele Schichten entstehen hierarchische Merkmale:
- untere Schichten erfassen lokale Muster und Syntax,
- mittlere Schichten lernen Beziehungen und Strukturen,
- tiefere Schichten kodieren abstraktere semantische Informationen.
Genau deshalb gehören LLMs klar in den Bereich des Deep Learning.
Vertiefung lesen: Neuronale Netzwerke hinter LLMs
Sprache als mathematisches Problem
Ein Satz wie „Das Wetter ist heute sehr ...“ wird vom Modell intern nicht als Bedeutung interpretiert, sondern als Sequenz von Symbolen.
Die Aufgabe des Modells ist: Welches Token kommt als nächstes mit der höchsten Wahrscheinlichkeit?
Mathematisch basiert das auf der Kettenregel der Wahrscheinlichkeit:
\[ P(x_1, x_2, ..., x_n) = \prod_{t=1}^{n} P(x_t \mid x_1, ..., x_{t-1}) \]
Das bedeutet: Die Wahrscheinlichkeit eines gesamten Satzes ergibt sich aus den Wahrscheinlichkeiten jedes einzelnen nächsten Tokens, jeweils basierend auf dem bisherigen Kontext.
Autoregressives Prinzip (der Kern von ChatGPT)
Ein LLM arbeitet autoregressiv. Das heisst:
- Es bekommt einen Starttext (Prompt).
- Es berechnet die Wahrscheinlichkeiten für das nächste Token.
- Es wählt ein Token aus.
- Dieses wird zum Kontext hinzugefügt.
- Der Prozess wiederholt sich.
So entsteht Schritt für Schritt ein kompletter Text.
Wichtig: Das Modell kennt den „ganzen Satz“ nicht im Voraus – es generiert ihn Token für Token.
Was sind Tokens eigentlich?
Ein Token ist die kleinste Einheit, mit der ein LLM arbeitet. Das kann sein:
- ein ganzes Wort,
- ein Wortteil (z. B. „ing“, „tion“),
- oder sogar einzelne Zeichen.
Beispiel: „unbelievable“ wird zu „un“, „believ“, „able“ zerlegt.
Diese Zerlegung nennt man Tokenisierung und sie ist entscheidend für die Effizienz des Modells.
Warum das funktioniert
Durch das Training auf riesigen Textmengen lernt das Modell unter anderem:
- Grammatik und Satzstruktur,
- typische Wortkombinationen,
- logische Zusammenhänge,
- stilistische Muster.
Obwohl es keine „echte Bedeutung“ kennt, kann es dadurch erstaunlich gut Texte schreiben, Fragen beantworten, Code generieren und komplexe Themen erklären.
Wichtiges Verständnis: Ein LLM versteht nicht wirklich wie ein Mensch, denkt nicht aktiv nach und hat kein Wissen im klassischen Sinn. Es ist ein extrem leistungsfähiger statistischer Mustererkenner.
2. Der Kernmechanismus: Next-Token-Prediction
Kernidee: Ein LLM erzeugt Text autoregressiv, indem es fortlaufend das nächste Token aus einer Wahrscheinlichkeitsverteilung auswählt.
In jedem Schritt berechnet das Modell eine Wahrscheinlichkeitsverteilung über das nächste Token. Formal:
P(t_{k+1} \mid t_1, t_2, ..., t_k)
Das ausgewählte Token wird an den bisherigen Kontext angehängt, dann folgt der nächste Schritt. Diese rekursive Erzeugung macht aus lokalen Entscheidungen Zusammenhängende Texte.
Autoregressiver Ablauf in der Praxis
Dieser Ablauf ist der operative Kern jeder LLM-Antwort. Aus vielen lokalen Einzelschritten entsteht dadurch ein global zusammenhängender Text.
- Ein Prompt startet den Kontext,
- das Modell berechnet Logits für das nächste Token,
- Softmax erzeugt Wahrscheinlichkeiten,
- ein Token wird gewählt (z. B. Greedy oder Sampling),
- das Token wird angehängt und der Prozess wiederholt.
Genau diese Schleife wird je nach Antwortlänge dutzende oder hunderte Male wiederholt. Die Qualität des Ergebnisses hängt deshalb sowohl vom Modell als auch von der Wahl der Sampling-Strategie ab.
Kleines Intuitionsbeispiel
Kontext: „Das Wetter ist heute ...“
Mögliche nächste Tokens könnten Wahrscheinlichkeiten wie 0.42 („sonnig“), 0.25 („kalt“), 0.11 („regnerisch“) usw. erhalten.
Das Modell „kennt“ den Satz nicht im Voraus, sondern entscheidet Schritt für Schritt.
Warum das so gut funktioniert
- lokale Vorhersagen werden zu global kohärentem Text verkettet,
- der gesamte bisherige Kontext geht in jeden Schritt ein,
- das Verfahren skaliert sehr gut auf grosse Modelle und Datensätze.
3. Embeddings & Vektorräume - wie ein LLM Bedeutung repräsentiert
Kernidee: Ein LLM verarbeitet keine Wörter direkt, sondern Vektoren in einem hochdimensionalen Raum.
Nach der Tokenisierung wird jedes Token über eine Embedding-Matrix in einen Vektor überführt. Erst dadurch kann ein neuronales Netzwerk Sprache mathematisch verarbeiten.
\[ e_i = E[x_i], \qquad E \in \mathbb{R}^{V \times d} \]
In diesem Raum werden semantische Beziehungen geometrisch darstellbar: ähnliche Begriffe liegen näher beieinander, unterschiedliche weiter auseinander. In modernen LLMs sind diese Repräsentationen zusätzlich kontextabhängig, das heisst dasselbe Wort kann je nach Satz unterschiedliche interne Vektoren erhalten.
Embeddings bilden damit die Grundlage für Attention, Kontextmodellierung und die gesamte weitere Verarbeitung im Transformer.
Vertiefung lesen: Embeddings und Vektorräume in neuronalen Netzen
4. Die Transformer-Architektur - das Herz eines LLM
Warum dieses Kapitel wichtig ist: Der Transformer ist der zentrale Grund für die Leistungsfähigkeit moderner LLMs.
Praktisch alle modernen Large Language Models - inklusive ChatGPT - basieren auf der Architektur Transformer. Sie wurde 2017 eingeführt und hat die Sprachverarbeitung grundlegend verändert.
Technisch ist der Transformer selbst ein neuronales Netzwerk: Er besteht aus vielen trainierbaren Gewichtsmatrizen, nichtlinearen Transformationen und gestapelten Schichten. Wenn man also sagt, ein LLM sei ein neuronales Netzwerk, dann meint man in der Praxis meist: ein sehr grosses Transformer-Netzwerk für Sprache.
Ein Transformer-Block kombiniert im Kern vier Elemente:
- Self-Attention für globale Kontextkopplung,
- Feed-Forward-Netzwerke für nichtlineare Merkmalsverarbeitung,
- Residual-Verbindungen für stabilen Gradientfluss,
- LayerNorm zur Stabilisierung der Aktivierungen.
Der mathematische Kern der Attention lautet:
\[ \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
Dadurch kann jedes Token dynamisch gewichten, welche anderen Positionen im Kontext gerade relevant sind. Multi-Head Attention erweitert dieses Prinzip um mehrere parallele Perspektiven, und die Kausalmaske erzwingt, dass ein Sprachmodell nicht in die Zukunft schaut.
Genau diese Architektur macht LLMs so leistungsfähig: globale Abhängigkeiten, parallele Verarbeitung und gute Skalierbarkeit auf sehr grosse Modelle.
Vertiefung lesen: Wie funktioniert ein Transformer?
5. Numerische Stabilität & Training Tricks in LLMs
Kernpunkt: LLM-Training ist nicht nur Optimierung, sondern auch ein numerisches Stabilitätsproblem.
Das Training eines Large Language Models ist nicht nur ein mathematisches Problem, sondern auch ein numerisches Stabilitätsproblem. Ohne spezielle Techniken würde das Training häufig divergieren, NaN-Werte erzeugen oder gar nicht sauber konvergieren.
Problem: Extreme Wertebereiche
Während des Trainings entstehen gleichzeitig sehr grosse und sehr kleine Werte (Overflow/Underflow).
\[ e^{100} \gg e^{-100} \]
Das führt zu instabiler Softmax und unbrauchbaren Gradienten.
Log-Sum-Exp Trick (zentral)
Softmax wird numerisch stabil berechnet als:
\[ \mathrm{softmax}(z_i)=\frac{e^{z_i-\max(z)}}{\sum_j e^{z_j-\max(z)}} \]
Effekt: Overflow wird vermieden, die relativen Wahrscheinlichkeiten bleiben identisch.
Softmax-Sättigung und Attention-Skalierung
Wenn ein Logit dominiert (\(z_i \gg z_j\)), wird die Verteilung fast One-Hot und der Gradient sehr klein.
In der Attention hilft die Skalierung:
\[ \frac{QK^T}{\sqrt{d_k}} \]
Sie verhindert zu grosse Dot-Produkte und hält Softmax im lernbaren Bereich.
Mixed Precision Training
Moderne LLMs nutzen meist FP16/BF16 für Geschwindigkeit und FP32 für kritische stabile Rechenschritte.
Da FP16 weniger Dynamik hat, wird oft Loss Scaling eingesetzt:
\[ g' = g \cdot S,\qquad g=\frac{g'}{S} \]
Damit wird Underflow reduziert und das Training stabilisiert.
Gradient Clipping
Bei explodierenden Gradienten (\(\lVert g\rVert \to \infty\)) werden Updates instabil. Clipping begrenzt die Norm:
\[ g=\frac{g}{\lVert g\rVert}\cdot c \]
Typisch ist \(c=1.0\).
LayerNorm und Residual-Verbindungen
LayerNorm stabilisiert Aktivierungen im Block:
\[ \mathrm{LayerNorm}(x)=\frac{x-\mu}{\sigma} \]
Residuals verbessern den Gradientfluss:
\[ y=x+f(x) \]
Beides ist entscheidend für tiefe Transformer-Netzwerke.
Aktivierungsfunktionen und Trade-offs
GELU und SwiGLU liefern glattere Gradienten und oft bessere Konvergenz als einfache Alternativen.
Techniken wie Activation Checkpointing oder ZeRO/FSDP sparen Speicher, erhöhen aber Rechenaufwand und Komplexität im Debugging.
NaN-Probleme in der Praxis
Typische Ursachen sind zu hohe Learning Rate, schlechte Initialisierung, Overflow in Softmax oder FP16-Effekte.
Praktisches Debugging: Gradient-Normen prüfen, Loss überwachen und Aktivierungs-/Logit-Bereiche loggen.
PyTorch in der Praxis - numerisch stabile LLM-Implementierung
Die meisten modernen LLMs werden mit Frameworks wie PyTorch implementiert. Viele Stabilitätsmechanismen sind dort bereits direkt integriert.
Stabile Cross-Entropy
Statt Softmax + Log manuell zu berechnen, wird direkt genutzt:
import torch.nn.functional as F
loss = F.cross_entropy(logits, targets)
Intern laufen numerisch stabile Schritte wie log_softmax (mit log-sum-exp) und Negative Log-Likelihood.
Das ist stabiler und meist schneller (fused kernels).
Mixed Precision mit AMP
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
logits = model(x)
loss = F.cross_entropy(logits, y)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()Damit werden FP16/BF16 und FP32 automatisch kombiniert, inklusive Loss Scaling für stabile Gradienten.
In der Praxis reduziert das die Rechenzeit und den Speicherbedarf erheblich. Gleichzeitig bleibt die numerische Stabilität deutlich besser erhalten als bei einer naiven FP16-Ausführung.
Gradient Clipping direkt im Framework
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)Das begrenzt explodierende Gradienten und verhindert instabile Updates.
Gerade bei tiefen Netzen und grossen Batches ist das ein wichtiger Sicherheitsmechanismus. Ohne Clipping können einzelne Ausreisser den gesamten Optimierungsschritt unbrauchbar machen.
Typische Best Practices
In produktionsnahen Trainingspipelines haben sich einige Kombinationen als besonders robust erwiesen. Sie adressieren gleichzeitig Optimierung, Stabilität und Effizienz.
- AdamW als Optimizer,
- AMP aktiviert,
- Gradient Clipping aktiv,
F.cross_entropystatt manueller Softmax-Implementierung.
Diese Kombination entspricht in vielen LLM-Trainingspipelines dem Industriestandard.
Fazit PyTorch
PyTorch abstrahiert viele komplexe Details auf wenige Zeilen Code. Trotzdem bleibt das Verständnis numerischer Stabilität entscheidend, um Fehler sauber zu debuggen, Training zu optimieren und grosse Modelle robust zu betreiben.
Fazit dieses Kapitels
Numerische Stabilität ist kein Detail, sondern eine Grundvoraussetzung für trainierbare LLMs in dieser Grössenordnung. Erst die Kombination aus stabiler Softmax, Scaling, Clipping, LayerNorm und Residuals macht robuste Trainingsläufe möglich.
6. Distributed Training & Systemdesign von LLMs
Kernpunkt: Modelle dieser Grössenordnung sind nur mit verteiltem Training und effizientem Systemdesign realisierbar.
Ein modernes Large Language Model kann nicht auf einer einzelnen Maschine trainiert werden. Grund sind Milliarden Parameter, enorme Datenmengen und ein sehr hoher Speicherbedarf für Parameter, Gradienten und Optimizer-Zustände.
Grundprinzip: Parallelisierung
Um die Last zu verteilen, wird Training auf viele GPUs aufgeteilt. Die wichtigsten Strategien sind:
Ohne diese Aufteilung würden sowohl Rechenzeit als auch Speicherbedarf schnell unpraktikabel werden. Parallelisierung ist deshalb keine optionale Optimierung, sondern eine Grundvoraussetzung moderner LLM-Entwicklung.
Data Parallelism
Jede GPU enthält eine vollständige Modellkopie und verarbeitet unterschiedliche Batches.
Nach jedem Schritt werden Gradienten gemittelt:
\[ g=\frac{1}{N}\sum_{i=1}^{N} g_i \]
Das ist einfach und verbreitet, funktioniert aber nur, wenn das Modell in eine GPU passt.
Model Parallelism
Hier wird das Modell selbst aufgeteilt, z. B. über:
- Tensor Parallelism (Aufteilung innerhalb von Layern),
- Pipeline Parallelism (Aufteilung über Layer hinweg).
Das ist für sehr grosse Modelle nötig, erhöht aber den Kommunikationsaufwand.
Speicheroptimierung (ZeRO / FSDP)
Statt komplette Replikate zu halten, werden Parameter, Gradienten und Optimizer-Zustände über mehrere GPUs verteilt. Das reduziert den Speicherbedarf drastisch und ermöglicht extrem grosse Modelle.
Zentrales Problem: Kommunikation
In grossen Clustern limitiert oft nicht die reine Rechenleistung, sondern der Datenaustausch zwischen GPUs. Effiziente Synchronisation und Netzwerk-Topologie sind deshalb entscheidend für die Gesamteffizienz.
Reale Trainingssysteme
Moderne LLMs laufen auf Clustern mit hunderten bis tausenden GPUs, Hochgeschwindigkeitsnetzwerken und verteilten Speichersystemen. Training wird dadurch zu einem Zusammenspiel aus Software, Hardware und Netzwerktechnik.
Einfluss auf den GPU-Markt
Der hohe Compute-Bedarf wirkt direkt auf die reale Wirtschaft:
- starke Nachfrage durch KI-Training,
- begrenzte Produktionskapazitäten,
- Fokus auf Rechenzentren statt Consumer-Hardware.
Folgen sind steigende GPU-Preise, längere Lieferzeiten und hohe Einstiegskosten für KI-Entwicklung.
Fazit dieses Kapitels
Distributed Training ist die Voraussetzung für moderne LLMs. Es zeigt klar: LLM-Entwicklung ist nicht nur Mathematik, sondern auch Infrastruktur-, Skalierungs- und Wirtschaftsthema.
7. Training eines Large Language Models - Mathematik & Optimierung
Kernidee: Training bedeutet, Vorhersagefehler zu minimieren und Parameter iterativ so anzupassen, dass echte Texte unter dem Modell wahrscheinlicher werden.
Ein Large Language Model wird trainiert, indem es lernt, die Wahrscheinlichkeitsverteilung über das nächste Token möglichst genau vorherzusagen. Formal approximiert das Modell:
\[ P(x_t \mid x_1, x_2, ..., x_{t-1}) \]
Zielfunktion: Maximum Likelihood
Das Training basiert auf Maximum Likelihood Estimation (MLE). für eine Sequenz \(x_1, ..., x_n\) wird maximiert:
\[ \mathcal{L} = \sum_{t=1}^{n} \log P_{\theta}(x_t \mid x_1, ..., x_{t-1}) \]
Intuition: Echte Texte sollen unter dem Modell hohe Wahrscheinlichkeit bekommen. Gute Vorhersagen erhoehen das Ziel, schlechte senken es.
Cross-Entropy Loss (praktische Form)
In der Implementierung wird meist Kreuzentropie minimiert:
\[ \mathcal{L} = -\sum_{i} y_i \log p_i \]
- \(y_i\): echtes Token (One-Hot),
- \(p_i\): vorhergesagte Modellwahrscheinlichkeit.
Perfekte Vorhersage führt zu sehr kleinem Loss, falsche Vorhersagen zu grossem Loss. Das ist genau die negative Log-Likelihood.
Perplexity - wie gut ist das Modell?
Eine wichtige Metrik für Sprachmodelle ist die Perplexity:
\[ \mathrm{Perplexity} = \exp\left(\frac{1}{n}\sum \mathrm{Loss}\right) \]
- Wert 10: Modell ist unsicher zwischen grob 10 Tokens,
- Wert 2: sehr gut,
- Wert 1: theoretisch perfekt.
Je kleiner die Perplexity, desto besser passt das Modell zur Datenverteilung.
Backpropagation durch den Transformer
Ein Trainingsschritt folgt immer demselben Schema:
- Forward Pass (Vorhersage),
- Loss berechnen,
- Gradienten berechnen,
- Parameter updaten.
Diese Abfolge verbindet Vorwärtsmodell, Fehlerfunktion und Optimierung zu einem einzigen Lernprozess. Ohne Backpropagation wäre es praktisch nicht möglich, Milliarden Parameter gezielt zu verbessern.
Wichtige Gradienteneigenschaft
für Softmax + Cross-Entropy gilt:
\[ \frac{\partial \mathcal{L}}{\partial z_i} = p_i - y_i \]
Diese Form ist rechnerisch effizient, numerisch stabil und einer der Gründe, warum diese Kombination in fast allen LLMs eingesetzt wird.
Optimierung mit Adam / AdamW
In der Praxis wird meist Adam bzw. AdamW verwendet. Adam nutzt gleitende Schätzungen von Mittelwert und Varianz der Gradienten:
\[ m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t \]
\[ v_t = \beta_2 v_{t-1} + (1-\beta_2) g_t^2 \]
\[ \theta_t = \theta_{t-1} - \eta \frac{m_t}{\sqrt{v_t} + \epsilon} \]
AdamW ergänzt Weight Decay und verbessert so die Regularisierung bei grossen Modellen.
Trainings-Stabilität (entscheidend)
Damit das Training grosser Modelle überhaupt zuverlässig läuft, müssen mehrere Stabilitätsmechanismen gleichzeitig zusammenspielen. Jeder einzelne adressiert dabei eine andere Fehlerquelle im Optimierungsprozess.
- Gradient Clipping: \(\lVert g \rVert \le c\), verhindert explodierende Gradienten.
- Learning-Rate-Schedule: Warmup, danach häufig Cosine Decay.
- Mixed Precision: FP16/BF16 für Speed, FP32 für kritische Stabilitätsanteile.
Erst die Kombination dieser Techniken macht das Training über lange Zeiträume hinweg reproduzierbar und stabil. In der Praxis ist Stabilität oft genauso wichtig wie rohe Modellgrösse.
Warum Training so teuer ist
Der Compute-Aufwand skaliert grob mit Parameterzahl und Datenmenge:
\[ \mathrm{Compute} \propto N \cdot D \]
Mit Milliarden Parametern und sehr grossen Tokenmengen entstehen extrem hohe FLOP-Kosten.
Speicherproblem bei grossen Modellen
Gespeichert werden müssen Parameter, Gradienten und Optimizer-States. Bei Adam bedeutet das häufig etwa das Drei- bis Vierfache der reinen ModellGrösse.
Typische Gegenmassnahmen:
- ZeRO (Sharding),
- FSDP,
- Activation Checkpointing.
Trainingspipeline (realistisch)
Ein echter Trainingsloop umfasst:
- Tokenisierung (BPE / Byte-Level),
- Batch-Erstellung,
- Forward durch den Transformer,
- Loss-Berechnung,
- Backpropagation,
- Optimizer Step.
Dieser Zyklus wird über sehr viele Schritte wiederholt.
Fazit dieses Kapitels
Das Training eines LLM bedeutet im Kern: Wahrscheinlichkeiten lernen, Fehler minimieren und Parameter iterativ optimieren. In der Praxis kommen jedoch extreme Datenmengen, hochkomplexe Optimierung und massive Hardwarekosten hinzu.
Verbindung zur Elektrotechnik - Signalverarbeitung & Systeme
Auch wenn Large Language Models primär aus der Informatik stammen, haben sie eine starke Verbindung zur Elektrotechnik - besonders zur Signalverarbeitung und Systemtheorie. Viele grundlegende Konzepte sind für Elektrotechniker bereits vertraut.
Neuronale Netze als Signalverarbeitungssysteme
Ein LLM kann als mehrstufiges System interpretiert werden:
\[ y=f(x) \]
Das ist vergleichbar mit digitalen Filtern, Übertragungsfunktionen und nichtlinearen Systemen: Jede Schicht transformiert ein Eingangssignal (Token-Vektoren) in ein Ausgangssignal.
Attention als dynamischer Filter
Self-Attention lässt sich schreiben als:
\[ y_i=\sum_j w_{ij}x_j \]
Vergleich: Ein FIR-Filter hat feste Koeffizienten, Attention hat adaptive Koeffizienten, die vom aktuellen Signal abhängen. Klassische Systeme sind oft statisch, LLMs dagegen dynamisch und kontextabhängig.
Frequenz- und Informationssicht
Auch ohne explizite Fourier-Transformation zeigen sich Parallelen: frühe Layer lernen eher lokale Muster, tiefere Layer abstraktere Information - ähnlich zu mehrstufigen Filterketten und Feature-Extraktion.
Diese Sicht ist besonders für Ingenieure hilfreich, weil sie den Sprung von klassischer Signalverarbeitung zu LLMs kleiner macht. Das Modell arbeitet zwar auf Sprache, aber viele Strukturideen erinnern an bekannte mehrstufige Verarbeitungsketten.
Optimierung als Systemidentifikation
Training kann als Systemidentifikation gelesen werden:
\[ \theta^*=\arg\min_{\theta} L(\theta) \]
Ziel ist die bestmögliche Approximation eines unbekannten Systems auf Basis von Messdaten (hier: Text).
Hardware-Bezug
GPUs führen massiv parallele Matrixoperationen aus - konzeptionell nahe an DSP- und FPGA-Beschleunigung: Parallelisierung, Speicherbandbreite und Latenzoptimierung sind zentrale gemeinsame Prinzipien.
Der Unterschied liegt vor allem in der Grössenordnung und im Software-Stack, nicht im Grundprinzip der effizienten numerischen Verarbeitung. Auch hier zeigt sich, dass moderne KI stark auf klassische Ingenieursdisziplinen aufbaut.
Fazit für Elektrotechniker
Ein LLM ist kein völlig fremdes Konzept, sondern eine Kombination aus Signalverarbeitung, linearen Systemen, nichtlinearer Optimierung und hochparalleler Hardware. Der grosse Unterschied liegt primär in Skalierung und Adaptivität.
8. Skalierungsgesetze von LLMs - warum grosse Modelle besser werden
Eine der wichtigsten Erkenntnisse moderner KI-Forschung ist: Die Leistung von Sprachmodellen folgt stabilen mathematischen Mustern. Diese Zusammenhänge nennt man Scaling Laws.
Grundidee: Mehr von allem verbessert die Leistung
Ein LLM wird typischerweise besser, wenn drei Grössen wachsen:
- Parameterzahl \(N\),
- Trainingsdaten \(D\),
- Rechenbudget \(C\).
Die Verbesserung folgt dabei nicht zufälligen Kurven, sondern robusten Potenzgesetzen.
Mathematisches Gesetz (Power Law)
Der Loss kann näherungsweise mit der ModellGrösse skaliert werden als:
\[ L(N) \propto N^{-\alpha} \]
Allgemeiner wird häufig modelliert:
\[ L(N,D,C) \approx aN^{-\alpha} + bD^{-\beta} + cC^{-\gamma} \]
Bedeutung: Mehr Parameter, mehr Daten und mehr Compute verbessern den Loss messbar, allerdings mit abnehmendem Grenznutzen.
Log-Log-Verhalten und Prognosen
In Log-Log-Darstellung liegen diese Beziehungen oft nahe an Geraden. Dadurch lassen sich Skalierungseffekte für künftige ModellGrössen relativ verlässlich abschätzen.
Compute-Optimalität (Chinchilla-Erkenntnis)
Ein zentraler Befund war, dass nicht nur die ModellGrösse zählt. Unter fixem Compute-Budget sollte die Balance zwischen Parametern und Daten stimmen. Vereinfacht:
\[ N \propto D \]
Viele frühere Modelle waren untertrainiert. Praktisch bedeutet das oft: Ein mittelgrosses Modell mit deutlich mehr Daten kann effizienter sein als ein extrem grosses Modell mit zu wenig Trainingsdaten.
Compute-Budget als harter Engpass
Der Trainingsaufwand skaliert grob mit:
\[ C \propto N \cdot D \]
Doppelte Parameter und doppelte Daten bedeuten nähert sich vierfachem Rechenaufwand.
Emergent Abilities
Ab bestimmten Grössenschwellen zeigen Modelle teils sprunghafte neue fähigkeiten, etwa in logischem Schliessen, übersetzen oder Programmieren. Diese Effekte nennt man emergente fähigkeiten.
Die Ursache ist nicht vollständig geklärt. Diskutiert werden Komplexitätsschwellen, robustere Generalisierung und reichere interne Repräsentationen.
Wichtige Einordnung
Auch bei starker Skalierung entsteht kein menschliches Verstehen. Das Modell bleibt ein statistischer Approximationapparat ohne Bewusstsein oder Intentionalität.
Grössere Modelle wirken oft kompetenter, weil ihre Approximation feiner und robuster wird. Das ändert aber nichts daran, dass das zugrunde liegende Prinzip weiterhin Wahrscheinlichkeitsmodellierung bleibt.
Grenzen der Skalierung
Skalierung verbessert Leistung oft zuverlässig, ist aber nicht grenzenlos fortsetzbar. Ab einem gewissen Punkt dominieren Kosten, Energiebedarf und Datenqualität die praktische Machbarkeit.
- Kosten und Energiebedarf steigen stark,
- hochwertige Daten werden knapper,
- Training wird bei extremen Skalen schwieriger stabil zu halten.
Deshalb liegt der Fokus heute zusätzlich auf effizienteren Architekturen und optimierten Trainingsverfahren.
Fazit dieses Kapitels
Scaling Laws zeigen klar: LLMs werden nicht zufällig besser, sondern folgen reproduzierbaren mathematischen Regeln. Mehr Parameter und mehr Daten helfen - aber nur im passenden verhältnis.
9. Inferenz & Sampling - wie ein LLM Texte generiert
Praxisrelevant: Das gleiche Modell kann je nach Sampling-Einstellung sehr unterschiedlich wirken - von stabil-sachlich bis kreativ-riskant.
Nach dem Training wird ein LLM in der Inferenz genutzt: Es erzeugt neuen Text basierend auf einem Prompt. Dabei läuft die Generierung autoregressiv, also Token für Token.
\[ x_{t+1} \sim P(x_{t+1} \mid x_1, ..., x_t) \]
Typischer Ablauf pro Schritt:
- Prompt/Kontext liegt vor,
- Modell berechnet Logits,
- Softmax erzeugt Wahrscheinlichkeiten,
- Sampling wählt ein Token,
- Token wird angehängt, dann Wiederholung.
Von Logits zu Wahrscheinlichkeiten
Die Roh-Ausgabe sind Logits \(z_i\). über Softmax werden sie in Wahrscheinlichkeiten umgerechnet:
\[ p_i = \frac{e^{z_i}}{\sum_j e^{z_j}} \]
Grosse Logits erhalten hohe Wahrscheinlichkeit, kleine fast 0. Praktisch wird das numerisch stabil mit log-sum-exp umgesetzt.
Sampling-Strategien
Das Modell muss nicht immer das Top-Token nehmen. Je nach Strategie ändern sich Stil, Vielfalt und Stabilität.
Genau an dieser Stelle wird aus derselben Verteilung ein sehr unterschiedliches Nutzererlebnis. Sampling ist deshalb nicht nur ein Implementierungsdetail, sondern ein zentraler Teil der praktischen Modellsteuerung.
Greedy Sampling
\[ x = \arg\max_i p_i \]
Vorteil: deterministisch und schnell. Nachteil: oft repetitiv und weniger Natürlich.
Greedy ist daher besonders für streng reproduzierbare oder sehr sachliche Ausgaben interessant. Für natürlich wirkende Dialoge ist diese Strategie oft zu starr.
Temperature
\[ p_i = \frac{e^{z_i/T}}{\sum_j e^{z_j/T}} \]
- \(T<1\): konservativer, fokussierter Output,
- \(T>1\): kreativer, aber riskanter.
Die Temperatur ist einer der wichtigsten Praxishebel für Stil und Diversität.
Kleine Änderungen an \(T\) können den Charakter einer Antwort stark verändern. Deshalb wird dieser Parameter in vielen Anwendungen bewusst an den jeweiligen Einsatzzweck angepasst.
Top-k Sampling
Nur die besten \(k\) Tokens bleiben im Kandidatenpool, der Rest wird verworfen. Danach wird aus diesen Kandidaten gesampelt.
Das reduziert sehr unwahrscheinliche und häufig unsinnige Token.
Top-p (Nucleus Sampling)
Hier wird dynamisch die kleinste Tokenmenge gewählt, deren kumulierte Wahrscheinlichkeit mindestens \(p\) erreicht:
\[ \sum_i p_i \ge p \]
Beispiel: \(p=0.9\) nutzt den wahrscheinlichsten 90%-Massebereich. Das passt sich dem Kontext flexibel an und ist in der Praxis sehr beliebt.
KV-Cache - warum Inferenz schnell wird
Ohne Caching müsste jedes neue Token die gesamte Attention wiederholen. Mit KV-Cache speichert das Modell Key/Value-Zustände vergangener Tokens.
Dadurch sinkt der inkrementelle Aufwand pro neuem Token deutlich (statt volle Rechenwiederholung über den gesamten bisherigen Kontext).
Speichertrade-off des KV-Caches
Der Cache wächst mit Kontextlänge, Modelldimension und Layeranzahl:
\[ \mathrm{Memory} \propto L \cdot d \cdot \mathrm{Layers} \]
Lange Kontexte verbessern oft Qualität, benötigen aber deutlich mehr Speicher.
Neural Text Degeneration
Falsche Sampling-Einstellungen können zu repetitiven, unnatürlichen Texten führen. Deshalb bestimmen Sampling-Strategie, Temperatur und Top-p/Top-k die wahrgenommene AntwortQualität massiv mit.
Determinismus vs. Kreativität
Zwischen maximaler Reproduzierbarkeit und maximaler Vielfalt besteht immer ein Zielkonflikt. Die passende Einstellung hängt davon ab, ob eher Präzision, Natürlichkeit oder kreative Breite gewünscht ist.
| Einstellung | Verhalten |
|---|---|
| Niedrige Temperatur + Greedy | Stabil, aber oft langweilig |
| Mittlere Temperatur + Top-p | Natürlich und ausgewogen |
| Hohe Temperatur | Kreativ, aber fehleranfälliger |
In produktiven Systemen wird deshalb oft ein mittlerer Bereich gewählt. Er liefert ausreichend stabile und gleichzeitig noch natürlich wirkende Antworten.
Warum Antworten variieren
Selbst bei gleichem Prompt können Antworten variieren, unter anderem durch Sampling-Zufall, numerische Unterschiede (Floating Point) und Parallelisierung.
Diese Variation ist also nicht automatisch ein Zeichen für Unzuverlässigkeit, sondern oft eine direkte Folge des gewählten Dekodierverfahrens. Wer exakte Reproduzierbarkeit braucht, muss Sampling und Laufzeitumgebung entsprechend kontrollieren.
Fazit dieses Kapitels
Textgenerierung in LLMs ist ein iterativer Sampling-Prozess über Wahrscheinlichkeitsverteilungen. Softmax liefert die Verteilung, Sampling trifft die Auswahl, KV-Cache sorgt für Geschwindigkeit - und die Parameter bestimmen Stil und Kreativität.
10. RLHF & Alignment - warum sich LLMs „menschlich“ verhalten
Kernpunkt: RLHF verändert vor allem das Verhalten des Modells (Hilfsbereitschaft, Sicherheit, Stil) - nicht den mathematischen Grundmechanismus.
Ein reines Sprachmodell mit Next-Token-Training kann zwar flüssig schreiben, aber ohne weitere Ausrichtung oft unstrukturierte, unfreundliche oder sogar riskante Antworten liefern. Deshalb wird es zusätzlich durch Alignment-Techniken angepasst, insbesondere durch Reinforcement Learning from Human Feedback (RLHF).
Ziel von Alignment
Statt nur den wahrscheinlichsten Text zu erzeugen, soll das Modell Antworten liefern, die für Menschen hilfreich, möglichst korrekt und sicher sind.
Alignment verschiebt also die Optimierungsrichtung von „wahrscheinlich“ zu „nützlich und akzeptabel“. Genau dadurch wirkt ein gut abgestimmtes Modell im Alltag deutlich hilfreicher.
Die RLHF-Pipeline (technisch)
Typischerweise besteht RLHF aus drei Schritten:
- Supervised Fine-Tuning (SFT): Menschen liefern hochwertige Beispielantworten.
- Reward Model: Menschen vergleichen Antworten (A besser als B), daraus lernt ein Bewertungsmodell.
- Reinforcement Learning (z. B. PPO): Das Sprachmodell wird auf hohen Reward optimiert.
Diese Pipeline trennt Demonstrationslernen, Präferenzlernen und Verhaltensoptimierung sauber voneinander. Dadurch lässt sich das Modell schrittweise auf menschliche Erwartungen ausrichten.
1) Supervised Fine-Tuning (SFT)
Auf kuratierten Frage-Antwort-Paaren lernt das Modell:
\[ P_{\theta}(\text{Antwort} \mid \text{Frage}) \]
Das ist weiterhin überwachtes Lernen, aber auf qualitativ besseren Daten als im breiten Vortraining.
2) Reward Model
Aus Präferenzdaten der Form \((x, y_{\text{better}}, y_{\text{worse}})\) wird ein Bewertungsmodell gelernt:
\[ R_{\phi}(x,y) \]
Es schätzt, wie gut eine Antwort aus menschlicher Sicht ist.
3) Reinforcement Learning mit PPO
Das eigentliche Modell wird dann so optimiert, dass erwarteter Reward steigt:
\[ \max_{\theta} \ \mathbb{E}[R_{\phi}(x,y)] \]
PPO (Proximal Policy Optimization) sorgt dafür, dass Updates kontrolliert bleiben und das Training stabilisiert wird.
\[ L_{\mathrm{PPO}} = \mathbb{E}\left[\min\left(r(\theta)A,\ \mathrm{clip}(r(\theta),1-\epsilon,1+\epsilon)A\right)\right] \]
Die Kernidee: Verbesserung, aber ohne zu grosse Policy-Sprünge.
Was das Modell dadurch lernt
RLHF wirkt vor allem auf Stil, Struktur und Sicherheitsverhalten der Antworten. Das Basiswissen des Modells wird dabei nicht neu erfunden, sondern anders priorisiert und präsentiert.
- höflicher und strukturierter zu antworten,
- Unsicherheit besser zu kommunizieren,
- riskante Inhalte eher zu vermeiden.
RLHF steuert also primär das Verhalten, nicht die grundlegende Architektur.
Wichtige Einordnung
Auch nach RLHF entsteht kein Bewusstsein und kein echtes Verstehen. Das Modell optimiert weiterhin statistisch, nur jetzt auf ein Ziel, das menschliche Präferenzen besser repräsentiert.
Trade-offs von Alignment
Alignment verbessert die Nutzbarkeit, ist aber nie kostenlos. Jede zusätzliche Sicherheits- oder Präferenzschicht verändert auch die Freiheitsgrade des Modells.
Vorteile:
- nutzbarere Antworten,
- bessere Sicherheit,
- angenehmere Interaktion.
Nachteile:
- Bias aus Feedbackdaten,
- Over-Alignment (zu vorsichtig),
- teilweise weniger kreative Freiheit.
In der Praxis muss daher immer ein Kompromiss zwischen Offenheit, Sicherheit und Nützlichkeit gefunden werden. Genau diese Balance ist eine der schwierigsten Designfragen moderner Assistenten.
Sicherheitsschichten zusätzlich zu RLHF
Neben RLHF kommen oft weitere Kontrollen hinzu:
- Content-Filter,
- Moderationssysteme,
- Systemrichtlinien.
Diese Ebenen greifen vor, während oder nach der eigentlichen Generierung ein. So entsteht ein mehrschichtiges Sicherheitssystem statt einer einzigen Kontrollinstanz.
Evaluation: Wie Qualität gemessen wird
Perplexity allein reicht nicht. In der Praxis werden kombiniert:
- menschliche Bewertungen,
- fachspezifische Benchmarks,
- Robustheits- und Sicherheitstests.
Das zeigt: Qualität ist bei Assistenten mehrdimensional.
Warum kleinere Modelle manchmal besser wirken
Ein kleineres, gut ausgerichtetes Modell kann nutzerseitig besser wirken als ein grösseres ohne Alignment, weil Verhalten und Antwortstil stark optimiert sind.
Wahrgenommene Qualität hängt also nicht nur von Wissen und Parameterzahl ab. Für viele Anwendungen ist die Interaktionsqualität mindestens ebenso entscheidend wie die reine Modellgrösse.
Fazit dieses Kapitels
RLHF ist ein Schlüssel dafür, dass moderne KI hilfreich, strukturiert und teilweise „menschlich“ wirkt. Es ändert nicht den Transformer-Kern, sondern die Zielrichtung des Verhaltens.
11. Grenzen und technische Risiken
- Halluzinationen: Plausibel klingende, aber faktisch falsche Aussagen.
- Bias: übernahme von Verzerrungen aus Trainingsdaten.
- Kontextlimit: Nur begrenzte Tokenzahl pro Anfrage.
- Kosten: Training und Inferenz benötigen viel Rechenleistung.
12. Fazit
Large Language Models wirken auf den ersten Blick wie intelligente Systeme, die Sprache verstehen, denken und logisch argumentieren können. Im Kern basieren sie jedoch auf einem klaren Prinzip: Sie modellieren Wahrscheinlichkeiten über Sprache.
Durch die Kombination aus mathematischer Optimierung (Loss-Minimierung), skalierbaren Architekturen (Transformer), riesigen Datenmengen und gezieltem Feintuning (RLHF) entsteht ein System, das Sprache extrem präzise nachbilden kann.
Die eigentliche „Magie“
Die Stärke eines LLMs liegt nicht in echtem Verständnis, sondern in hochdimensionalen Vektorräumen, komplexer Mustererkennung und emergenten fähigkeiten durch Skalierung. Was wie Denken wirkt, ist letztlich eine sehr gute Approximation statistischer Zusammenhänge.
Die scheinbare Magie entsteht also aus dem Zusammenspiel vieler bekannter technischer Bausteine. Beeindruckend wird das System vor allem durch Grössenordnung, Trainingsdaten und Optimierungstiefe.
Technik trifft Realität
Ein modernes LLM ist gleichzeitig:
- ein tiefes neuronales Netzwerk,
- ein Optimierungsproblem mit Milliarden Parametern,
- ein verteiltes Hochleistungs-Rechensystem,
- und ein durch Menschen ausgerichtetes Werkzeug.
Es verbindet Theorie, Mathematik und Engineering auf hohem Niveau.
Blick in die Zukunft
Aktuelle Entwicklungen gehen vor allem in Richtung:
- effizientere Modelle (weniger Compute bei gleicher Leistung),
- längere Kontextfenster,
- bessere Multimodalität (Text, Bild, Audio),
- stärkeres Alignment und mehr Sicherheit.
Die grundlegenden Prinzipien bleiben dabei dieselben.
Schlussgedanke
Ein Large Language Model ist kein denkendes Wesen, sondern ein extrem leistungsfähiges Werkzeug. Genau diese Kombination aus Einfachheit im Prinzip und Komplexität in der Umsetzung macht LLMs zu einer der bedeutendsten Technologien unserer Zeit.
Autor: Ruedi von Kryentech
Erstellt am: 14.04.2026 · Zuletzt aktualisiert: 14.04.2026
Fachlicher Stand zum Zeitpunkt der letzten Aktualisierung.