異常検知のためのオートエンコーダ
ニューラルネットによる再構成ベースの故障検出
オートエンコーダによる異常検知とは?
オートエンコーダは、正常なシステム挙動を学習し、 そこからのずれを自動的に検出するよう訓練されたニューラルネットです。
典型的な用途には次のようなものがあります。
- 電気信号の監視
- 油圧システムにおける故障検出
- 機械の状態監視(コンディション・モニタリング)
- サイバーセキュリティ(異常な挙動の検出)
この手法は教師なし異常検知(unsupervised anomaly detection)に属し、 産業、IoT、機械学習の分野で広く使われています。
1. 動機
電気信号、油圧設備、センサ監視などの技術システムでは、しばしば次の問いが立ちます。明示的な故障モデルがないとき、故障をどう検出するか?
洗練された答えの一つが、オートエンコーダによる再構成ベースの異常検知です。ニューラルネットは正常状態だけで訓練します。未知の状態や故障状態が現れると、再構成誤差が大きく跳ね上がります。
- 教師なし(故障ラベル不要)
- モデル不要(物理的な故障の記述が不要)
- 多数のセンサ信号へスケールしやすい
2. 直感的な説明
オートエンコーダは次の問いを学びます。「正常なシステム挙動はどのようなものか?」
既知の状態ではネットワークはよく再構成できます。未知の状態(例:センサ故障、ドリフト、欠陥)では信号をきれいに再現できず、誤差が大きくなります。
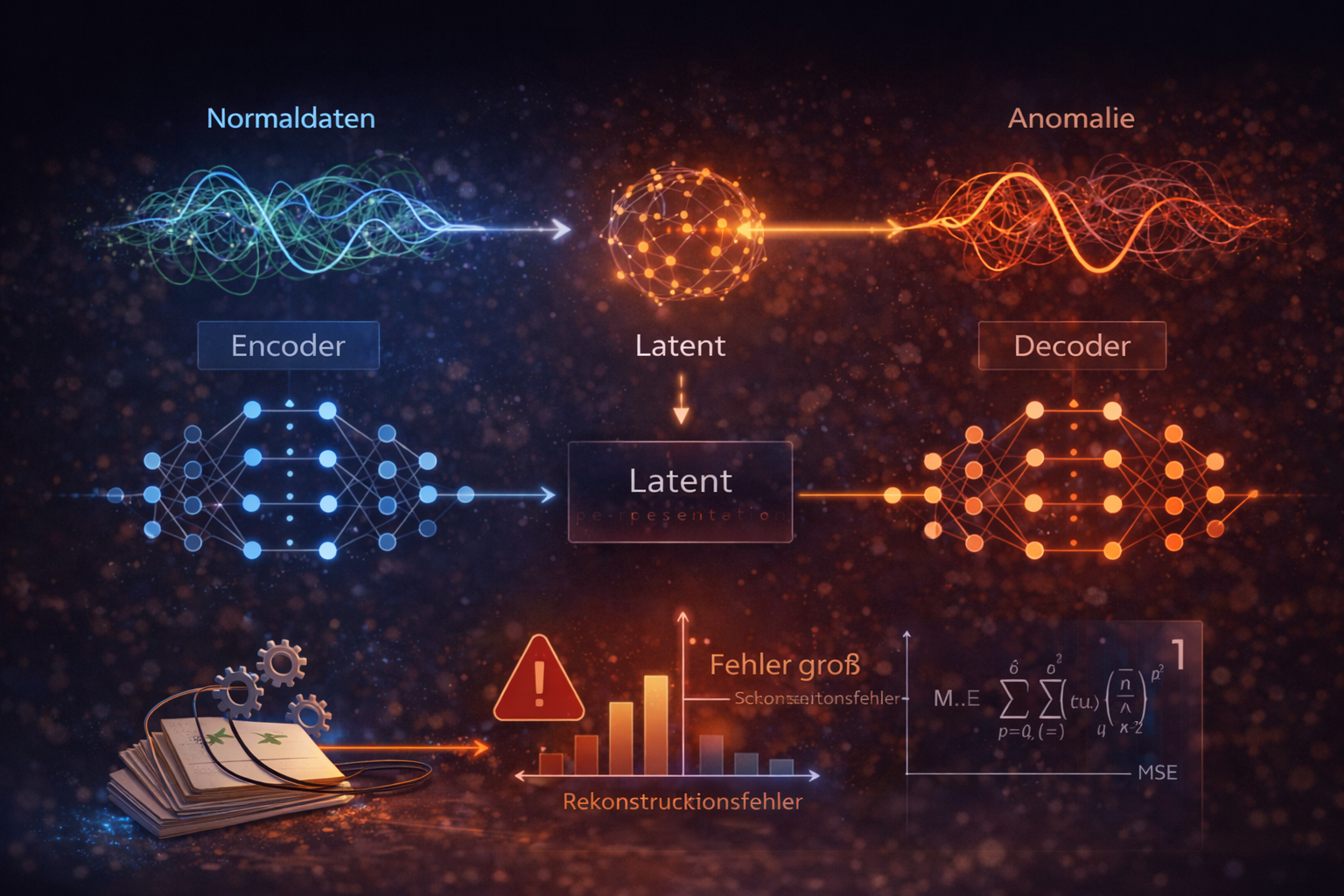
3. オートエンコーダの基本原理
オートエンコーダは三つの部分から成ります。
入力 \(x\) → エンコーダ → 潜在空間 \(z\) → デコーダ → 再構成 \(\hat{x}\)
エンコーダ: 入力信号を圧縮し、\(z = f(x)\) とします。
潜在空間: 重要な特徴を凝縮した表現です。
デコーダ: 入力信号を再構成し、\(\hat{x} = g(z)\) とします。
誤差の計算: 典型的には平均二乗誤差(MSE)を用います。
\[\mathrm{Loss} = ||x - \hat{x}||^2\]
誤差が定めた閾値を超えれば、その状態は異常としてフラグが立ちます。
オートエンコーダは次の関数を近似します。 \[ \hat{x} = g(f(x)) \] ここで \(f\) はエンコーダ、\(g\) はデコーダです。
目的は次の最小化です。 \[ \min ||x - g(f(x))||^2 \]
潜在空間は情報のボトルネックとして働き、 信号の最も重要な構造だけを通します。
潜在空間は低次元多様体への射影と捉えることができます。 正常データはこの構造の近くにあり、異常はその外側に位置します。
4. 小さな数値例
簡略化した2次元センサ系 \(x = (x_1, x_2)\) を考え、正常時は \(x_2 \approx x_1\) と仮定します。
線形ミニ・オートエンコーダ:
\[ z = 0.5x_1 + 0.5x_2,\quad \hat{x}_1 = z,\quad \hat{x}_2 = z \]
正常時: \(x = (2, 2.1)\)
\[ z = 2.05,\quad \hat{x} = (2.05, 2.05),\quad e = (-0.05, 0.05),\quad \mathrm{MSE} \approx 0.005 \]
非常に小さい → 正常状態。
故障時: \(x = (2, 5)\)
\[ z = 3.5,\quad \hat{x} = (3.5, 3.5),\quad e = (-1.5, 1.5),\quad \mathrm{MSE} = 4.5 \]
明らかに大きい → 異常。
5. 実務での利用(信号監視)
センサや電気信号の監視などの技術システムでは、 オートエンコーダによって正常状態を継続的に学習できます。
検出しうる典型的な故障には次のようなものがあります。
- センサのドリフト
- 通常範囲を外れたノイズ
- 急な信号の変化
- ハードウェア欠陥
6. Python(PyTorch)による実装
次の最小例では、オートエンコーダを正常データだけで訓練し、その後、正常サンプルと故障サンプルで誤差を比較します。
import torch
import torch.nn as nn
import torch.optim as optim
torch.manual_seed(0)
# 1) 訓練データ(正常状態):x2 は x1 に小さなノイズを加えたもの
n_samples = 1000
x1 = torch.randn(n_samples, 1)
x2 = x1 + 0.1 * torch.randn(n_samples, 1)
data = torch.cat((x1, x2), dim=1)
# 2) オートエンコーダ
class Autoencoder(nn.Module):
def __init__(self):
super().__init__()
self.encoder = nn.Sequential(
nn.Linear(2, 4),
nn.ReLU(),
nn.Linear(4, 1)
)
self.decoder = nn.Sequential(
nn.Linear(1, 4),
nn.ReLU(),
nn.Linear(4, 2)
)
def forward(self, x):
z = self.encoder(x)
x_hat = self.decoder(z)
return x_hat
model = Autoencoder()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
# 3) 訓練
for _ in range(200):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, data)
loss.backward()
optimizer.step()
# 4) テスト:正常状態と故障状態
normal_sample = torch.tensor([[2.0, 2.1]])
anomaly_sample = torch.tensor([[2.0, 5.0]])
error_normal = criterion(model(normal_sample), normal_sample)
error_anomaly = criterion(model(anomaly_sample), anomaly_sample)
print("Normal Error:", error_normal.item())
print("Anomaly Error:", error_anomaly.item())7. 閾値の決め方
閾値の選び方は決定的です。 低すぎると誤検知が増え、 高すぎると実際の故障を見逃します。
実務では、検証データを用いて閾値を調整することが多いです。
\[ \mathrm{Threshold} = \mu + 3\sigma \]
この値を超える誤差はすべて異常とみなします。
8. 実務でのオートエンコーダ:Pythonで訓練し、PLCで推論
実際の自動化システムでは、オートエンコーダをPLC上で直接訓練することは通常ありません。訓練はオフラインでPython(例:PyTorch)で行い、誤差逆伝播やAdamなどの最適化手法や大規模な訓練データが使えます。
訓練後に引き継ぐのは、学習済みのモデルパラメータだけです。
- エンコーダの重みとバイアス
- デコーダの重みとバイアス
- 選んだ活性化関数
PLC上ではその後、推論だけを実行します。つまり、現在の特徴ベクトルをエンコーダとデコーダに通し、信号を再構成し、再構成誤差を異常の指標として計算します。
この流れは産業用途に特に適しています。PLCは少数の演算だけを実行すればよく、それでも訓練済みニューラルモデルを利用できます。
FUNCTION_BLOCK Autoencoder_5_3_5
VAR_INPUT
enable : BOOL;
(* 特徴ベクトル *)
x1 : REAL;
x2 : REAL;
x3 : REAL;
x4 : REAL;
x5 : REAL;
threshold : REAL := 0.05;
END_VAR
VAR_OUTPUT
valid : BOOL;
anomaly : BOOL;
mse : REAL;
h1 : REAL; h2 : REAL; h3 : REAL;
x1_hat : REAL;
x2_hat : REAL;
x3_hat : REAL;
x4_hat : REAL;
x5_hat : REAL;
END_VAR
VAR
x : ARRAY[0..4] OF REAL;
h : ARRAY[0..2] OF REAL;
x_hat : ARRAY[0..4] OF REAL;
z : REAL;
err : REAL;
i, j : INT;
END_VAR
(* 初期化 *)
valid := FALSE;
anomaly := FALSE;
mse := 0.0;
IF enable THEN
x[0] := x1;
x[1] := x2;
x[2] := x3;
x[3] := x4;
x[4] := x5;
(* エンコーダ *)
FOR j := 0 TO 2 DO
z := 0.0;
FOR i := 0 TO 4 DO
z := z + x[i];
END_FOR
h[j] := TANH(z);
END_FOR
(* デコーダ *)
FOR i := 0 TO 4 DO
z := 0.0;
FOR j := 0 TO 2 DO
z := z + h[j];
END_FOR
x_hat[i] := z;
END_FOR
(* 誤差計算 *)
err := 0.0;
FOR i := 0 TO 4 DO
err := err + (x[i] - x_hat[i]) * (x[i] - x_hat[i]);
END_FOR
mse := err / 5.0;
anomaly := (mse > threshold);
valid := TRUE;
END_IF
構造化テキスト(ST)の例の構成
- 入力: プロセスからの正規化済み5特徴
- エンコーダ: 線形結合のあと tanh 活性化
- 潜在空間: 3変数への圧縮表現
- デコーダ: 元の特徴ベクトルの再構成
- 誤差解析: 平均二乗誤差(MSE)の計算
- 判定: 閾値との比較による異常検知
9. 長所と限界
長所:
- 故障モデルが不要
- 未知の故障も検出しうる
- 高次元センサデータに向く
- 教師なし学習
限界:
- 閾値の選び方が重要
- 代表的な正常データが不可欠
- ドリフトは検出品質を悪化させうる
10. まとめ
オートエンコーダによる異常検知は、技術システムに対して強力で柔軟なアプローチです。核となる考え方は圧縮 → 再構成 → 誤差解析です。
センサ信号が多い場合でも、明示的な故障クラスを定義せずに複雑な関係をモデル化できます。
著者: Ruedi von Kryentech
作成: 2026年4月6日 · 最終更新: 2026年4月6日
最終更新時点の技術的内容。