生体認証システムにおける誤り訂正符号
ノイズの多い生体計測を安全な鍵にどう活かすか
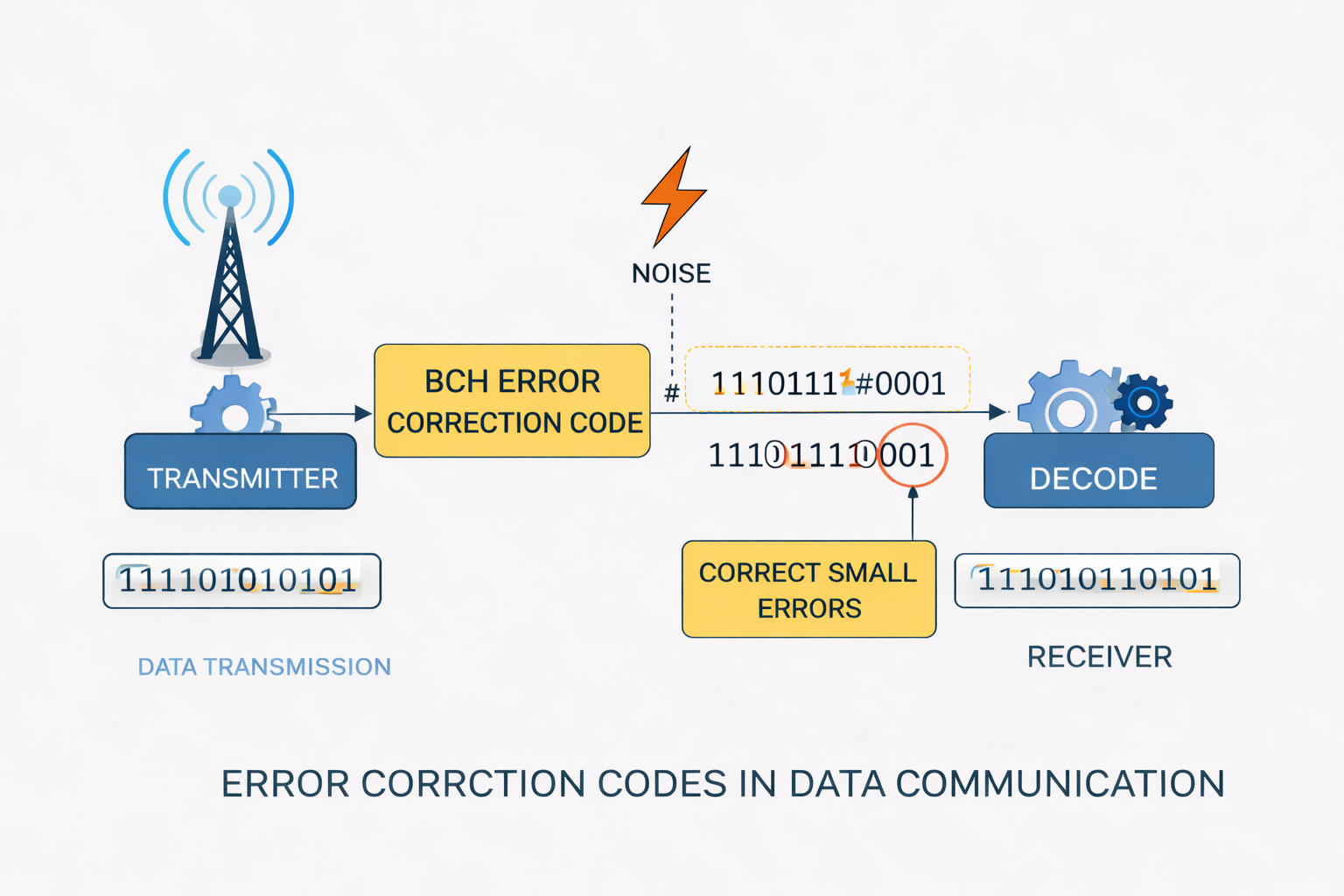
はじめに
電気工学科での学びの中で、誤り訂正はもともと通信システムの文脈、すなわち誤って伝送されたメッセージを訂正する話として知った。
しかし自著のVisuKeyプロジェクトでは、これらの概念が実測データにもそのまま当てはまることがすぐに分かった。とりわけ生体認証システムでの利用は興味深い。
例としては次のようなものがある。
- 指紋認識
- 顔認識
- 虹彩スキャナ
- 画像ベースの認証
このようなシステムの中心的な問題は、データの自然なばらつきである。同一人物の2回の計測が完全に一致することはない。
ここで誤り訂正符号が役に立つ。差異を吸収し、安定して再現可能な認証情報を得られる。
ノイズの多いデータという問題
生体データには常にある程度のノイズが乗る。
同じ画像を2回撮影すると、次のような要因で差が生じる。
- 照明
- カメラノイズ
- 視点(パースペクティブ)
- 画像圧縮
得られるデータパターンは似ているが同一ではない。
誤り訂正符号
誤り訂正符号はもともと通信システム向けに開発された。目的はビット誤りを検出し訂正することである。
送信側は冗長ビットを付加してデータを符号化し、受信側は誤りを検出・訂正できる。
反復符号――誤り訂正の入門
単純だが非常に分かりやすい誤り訂正符号に反復符号がある。各ビットを複数回送ることで伝送誤りを吸収する。
3重反復符号では次の対応となる。
0 → 000
1 → 111
復号は多数決である。形式的には、受信ベクトルrが最も近い有効なコード語に写像される。
有効なコード語の集合は次のとおり。
C = {000, 111}
最小ハミング距離は次のとおり。
d = 3
次が成り立つため、ちょうど1ビットの誤りを訂正できる。
t = ⌊(d - 1) / 2⌋ = 1
生成行列――体系的な符号の構成
反復符号は直感的だが、現代の符号は行列で記述される。生成行列Gが情報ビットからコード語への写像を定義する。
一般に次が成り立つ。
t = s · G
ここで
- s ∈ {0,1}k – メッセージベクトル
- G ∈ {0,1}k×n – 生成行列
- t ∈ {0,1}n – コード語
すべての演算はGF(2)上、すなわち法2(加算の代わりにXOR)で行う。
生成行列の系統形
多くの実用的な符号では、生成行列を系統形で書く。
G = [ Ik | P ]
ここで
- Ik – 単位行列(元データがそのまま残る)
- P – パリティ行列
すなわちコード語の先頭kビットが元データ、残りが冗長である。
例:(7,4)ハミング符号
生成行列は次のとおり。
G =
[ 1 0 0 0 | 1 1 0 ]
[ 0 1 0 0 | 1 0 1 ]
[ 0 0 1 0 | 0 1 1 ]
[ 0 0 0 1 | 1 1 1 ]
次のことが明らかである。
- 左:単位(データビット)
- 右:パリティ構造
計算例:
s = (1 0 1 0)
計算(法2):
t = s · G =
(1·行1) ⊕ (0·行2) ⊕ (1·行3) ⊕ (0·行4)
t = (1 0 0 0 1 1 0) ⊕ (0 0 1 0 0 1 1)
t = (1 0 1 0 1 0 1)
パリティ検査行列――誤り検出の構造
パリティ検査行列Hは、有効なコード語が満たすべき制約を表す。
有効なコード語に対して次が成り立つ。
H · tT = 0
すなわち各コード語はHの零空間に属する。
パリティ検査行列の構成
系統的符号では次が成り立つ。
H = [ PT | In-k ]
図に示す構造と一致する。
例:(7,4)ハミング符号
H =
[ 1 1 0 | 1 0 0 0 ]
[ 1 0 1 | 0 1 0 0 ]
[ 0 1 1 | 0 0 1 0 ]
シンドロームと誤り位置の特定
語rを受信したとき、シンドロームを計算する。
z = H · rT
- z = 0 → 誤りなし
- z ≠ 0 → 誤りあり
重要なのは、Hの各列がコード語の1ビットに対応することである。
シンドロームは列――すなわち誤ったビット――を直接指し示す。
例
受信:
r = (1 0 1 0 1 0 0)
計算:
z = H · rT = (0 1 0)
→ 列2に対応 → ビット2が誤り → 反転する
幾何学的解釈
コード語はn次元空間の点と見なせる。誤りは点をわずかにずらす。
復号はハミング距離の意味で最も近い有効なコード語への射影に相当する。
VisuKeyと生体データへの適用
VisuKeyの用途では、生体埋め込み(エンベディング)から二値ベクトルが得られる。
しかしこれらは安定しておらず、わずかな変化でビット誤りが生じる。
行列の構造がここで決定的である。
- Gが安定した符号化を定義する
- Hが一貫性を検査し誤りを検出する
- シンドロームが狙いを定めた訂正を可能にする
これによりノイズの多い生体信号が安定したコードに写像され、再現可能な暗号鍵の基盤となる。
生体システムにおける誤り訂正符号の利用
生体システムでは埋め込み(エンベディング)が用いられる。顔などの生体特徴を高次元ベクトルとして数値化したものである。
典型的な埋め込みは連続空間(例:ℝn)に存在する。暗号用途ではこれを安定した二値ベクトルに写す必要がある。
x ∈ ℝn → b ∈ {0,1}n
二値化は重要である。入力のわずかな変化(照明やポーズなど)がビット反転を招きうる。
形式的には、受信信号を摂動版として次のように書ける。
r = b ⊕ e
ここで
- b – 理想的な二値ベクトル
- e – 誤りベクトル(ノイズ)
誤り訂正符号の役割は、rから元のbを再構成することである。
安定性解析とビット選択
決定的なステップは安定ビットの選択である。埋め込みのすべてのビットが同じように信頼できるわけではない。
各ビットiについて、例えば複数回の計測から安定性指標を定義できる。
pi = P(bi が安定)
典型的な手法:
- 複数枚の画像にわたる分散解析
- 信号対雑音比(SNR)
- 反復間のハミング距離
高い安定性を示すビットだけを残す。
bstable = 選択(b, pi > 閾値)
これにより実効誤り率が大きく下がり、誤り訂正符号への要求も緩む。
ファジー抽出器――生体と暗号の接続
現代のシステムではファジー抽出器(fuzzy extractor)がよく使われる。
考え方は、ノイズの多い生体データから安定した暗号鍵を生成することである。
プロセスは二段階ある。
- 登録(エンロールメント):
b → (w, ヘルパーデータ) - 再構成:
r + ヘルパーデータ → b → 鍵
ヘルパーデータには誤り訂正符号に由来する情報が含まれるが、鍵そのものは漏らさない。
典型的には次が成り立つ。
w = Hash(b)
誤り訂正符号により、ノイズがあっても常に同じbが再構成される。
VisuKeyに適した誤り訂正符号はどれか
符号の選び方は誤り率とデータの構造に強く依存する。
1. ハミング符号
- 非常に効率的(冗長が小さい)
- 訂正できるのは1ビット誤りのみ
- 非常に安定したデータ向き
→ 生体システムには多くの場合弱すぎる。
2. BCH符号(VisuKeyで使用)
- 複数ビット誤りを訂正可能(tは設定可能)
- 柔軟なパラメータ (n, k, t)
- 解析が進み、効率的に実装しやすい
BCH符号は次を満たす。
dmin ≥ 2t + 1
→ t個の誤りを確実に訂正できる
典型例:
- (255, 131, t=15)
→ 埋め込みにおける中程度のノイズに適する
3. LDPC符号
- 高い誤り率でも非常に強い
- 反復復号
- 実装コストは高め
→ より強いノイズ向けの将来版で有望
4. リード・ソロモン符号
- ビットではなくシンボル単位で動作
- バースト誤りに強い
→ 二値化した埋め込みにはあまり向かない
なぜBCH符号がVisuKeyに適するか
VisuKeyでは、画像のわずかな変化によって誤りが分散したビット反転として現れることが多い。
BCH符号の性質はこれに合う。
- 誤りがランダムに分布 → BCHが適する
- 誤り率は中程度 → LDPCは不要
- 決定的な復号 → 出力が安定
さらにBCH符号はビット選択と組み合わせやすい。
実効誤り率 ↓ → より小さいtで足りる
VisuKeyにおける一連の流れ
- 画像を取得
- 埋め込みを計算(例:512次元)
- 二値化 → b
- 安定ビットを選択 → bstable
- BCH符号化を適用
- ヘルパーデータを保存
- 鍵を導出(ハッシュ)
再度読み取るとき:
- 新しいrが得られる
- 誤り訂正がbを再構成する
- 同一の鍵が生成される
まとめ
誤り訂正符号は、ノイズの多い生体データを安定した暗号鍵へ写すための中核である。
とりわけBCH符号は、効率、訂正能力、実装のしやすさのバランスに優れる。
信号処理、統計的ビット選択、符号化理論を組み合わせることで、ぼんやりした実測データからVisuKeyのように信頼でき安全な認証を実現できる。
著者: Ruedi von Kryentech
作成: 2026年4月6日 · 最終更新: 2026年4月6日
最終更新時点の技術的内容。