Error correction codes in biometric authentication systems
How noisy biometric measurements can be turned into secure keys
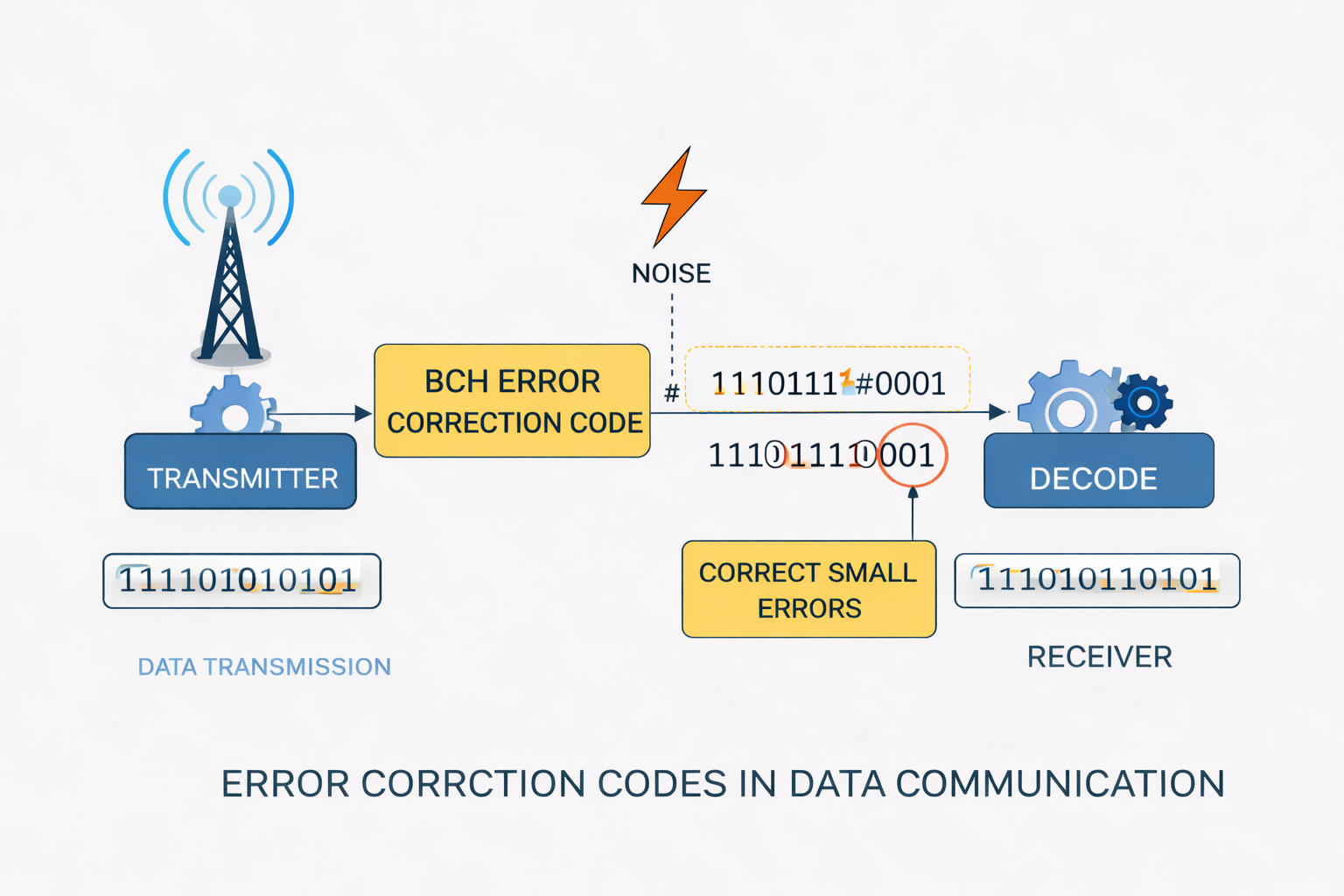
Introduction
During my electrical engineering studies, I first encountered error correction in the context of communication systems—that is, correcting incorrectly transmitted messages.
In my own VisuKey project, however, it quickly became clear that these concepts also apply to real-world measurement data. Their use in biometric authentication systems is particularly interesting.
Examples include:
- Fingerprint recognition
- Face recognition
- Iris scanners
- Image-based authentication
A central issue in such systems is the natural variability of the data. Two measurements of the same person are never exactly identical.
This is where error correction codes come in: they compensate for these differences and produce stable, reproducible authentication information.
The problem of noisy data
Biometric data always contain some amount of noise.
If an image is captured twice, differences arise due to:
- Lighting
- Camera noise
- Perspective
- Image compression
The resulting data pattern is similar, but not identical.
Error correction codes
Error correction codes were originally developed for communication systems. Their purpose is to detect and correct bit errors.
A sender encodes data with additional redundancy bits. The receiver can then detect and correct errors.
Repetition codes—an introduction to error correction
A simple but very illustrative error correction code is the repetition code. Each bit is transmitted multiple times so that transmission errors can be compensated.
For a triple repetition code:
0 → 000
1 → 111
Decoding uses majority voting. Formally, the received vector r is mapped to the nearest valid codeword.
The set of valid codewords is:
C = {000, 111}
The minimum Hamming distance is:
d = 3
Exactly one error can be corrected, because:
t = ⌊(d - 1) / 2⌋ = 1
Generator matrix—systematic construction of codes
While repetition codes are intuitive, modern codes are described using matrices. The generator matrix G defines the mapping from information bits to codewords.
In general:
t = s · G
with:
- s ∈ {0,1}k – message vector
- G ∈ {0,1}k×n – generator matrix
- t ∈ {0,1}n – codeword
All operations are in GF(2), i.e. modulo 2 (XOR instead of addition).
Systematic form of the generator matrix
In many practical codes, the generator matrix is written in systematic form:
G = [ Ik | P ]
with:
- Ik – identity matrix (original data preserved)
- P – parity matrix
This means: the first k bits of the codeword are the original data; the remaining bits are redundancy.
Example: (7,4) Hamming code
The generator matrix is:
G =
[ 1 0 0 0 | 1 1 0 ]
[ 0 1 0 0 | 1 0 1 ]
[ 0 0 1 0 | 0 1 1 ]
[ 0 0 0 1 | 1 1 1 ]
Here you can clearly see:
- left: identity (data bits)
- right: parity structure
Example calculation:
s = (1 0 1 0)
Computation (modulo 2):
t = s · G =
(1·row1) ⊕ (0·row2) ⊕ (1·row3) ⊕ (0·row4)
t = (1 0 0 0 1 1 0) ⊕ (0 0 1 0 0 1 1)
t = (1 0 1 0 1 0 1)
Parity-check matrix—structure of error detection
The parity-check matrix H describes the constraints that every valid codeword must satisfy.
For a valid codeword:
H · tT = 0
That is: every codeword lies in the null space of H.
Construction of the parity-check matrix
For systematic codes:
H = [ PT | In-k ]
This is exactly the structure shown in the diagrams.
Example (7,4) Hamming code:
H =
[ 1 1 0 | 1 0 0 0 ]
[ 1 0 1 | 0 1 0 0 ]
[ 0 1 1 | 0 0 1 0 ]
Syndrome and error localization
When a word r is received, the syndrome is computed:
z = H · rT
- z = 0 → no error
- z ≠ 0 → error present
Crucially: each column of H corresponds to one bit in the codeword.
The syndrome points directly to the column—and thus to the erroneous bit.
Example
Received:
r = (1 0 1 0 1 0 0)
Computation:
z = H · rT = (0 1 0)
→ corresponds to column 2 → bit 2 is wrong → invert it
Geometric interpretation
Codewords can be viewed as points in n-dimensional space. Errors shift the point slightly.
Decoding corresponds to projecting onto the nearest valid codeword in the Hamming sense.
Application to VisuKey and biometric data
In the VisuKey use case, binary vectors are produced from biometric embeddings.
These vectors are not stable—small changes cause bit errors.
The matrix structure is essential:
- G defines stable encoding
- H checks consistency and detects errors
- the syndrome enables targeted correction
This maps a noisy biometric signal onto a stable code—the basis for reproducible cryptographic keys.
Using error correction codes in biometric systems
Biometric systems use so-called embeddings: high-dimensional vectors that describe a biometric trait—for example a face—numerically.
A typical embedding lives in continuous space (e.g. ℝn). For cryptographic use, it must be turned into a stable binary vector:
x ∈ ℝn → b ∈ {0,1}n
This binarization is critical: small changes in the input (e.g. lighting or pose) can cause bit flips.
Formally, the received signal can be viewed as a perturbed version:
r = b ⊕ e
with:
- b – ideal binary vector
- e – error vector (noise)
The task of the error correction code is to reconstruct the original b from r.
Stability analysis and bit selection
A crucial step is selecting stable bits. Not all bits in an embedding are equally reliable.
For each bit i, a stability metric can be defined, e.g. from repeated measurements:
pi = P(bi stable)
Typical approaches:
- Variance analysis across multiple captures
- Signal-to-noise ratio (SNR)
- Hamming distance between repetitions
Only bits with high stability are kept:
bstable = select(b, pi > threshold)
This greatly reduces the effective error rate and eases the demands on the error correction code.
Fuzzy extractor—linking biometrics and cryptography
Modern systems often use the fuzzy extractor concept.
The idea: derive a stable cryptographic key from noisy biometric data.
The process has two phases:
- Enrollment:
b → (w, helper data) - Reconstruction:
r + helper data → b → key
The helper data contain information from the error correction code without revealing the key itself.
Typically:
w = Hash(b)
and the error correction code ensures that the same b is reconstructed despite noise.
Which error correction codes suit VisuKey?
The choice of code depends strongly on the error rate and structure of the data.
1. Hamming codes
- very efficient (low redundancy)
- correct only 1 bit error
- suitable only for very stable data
→ Usually too weak for biometric systems.
2. BCH codes (used in VisuKey)
- correct multiple bit errors (t configurable)
- flexible parameters (n, k, t)
- well analyzed and efficiently implementable
A BCH code satisfies:
dmin ≥ 2t + 1
→ can reliably correct t errors
Typical example:
- (255, 131, t=15)
→ suitable for moderate noise levels in embeddings
3. LDPC codes
- very strong at high error rates
- iterative decoding
- higher implementation effort
→ interesting for future versions with heavier noise
4. Reed–Solomon codes
- operate on symbols rather than bits
- robust to burst errors
→ less suitable for binarized embeddings
Why BCH codes are a good fit for VisuKey
In VisuKey, errors typically appear as distributed bit flips from small image changes.
BCH code properties match this well:
- errors are randomly distributed → BCH is a good fit
- moderate error rate → no need for LDPC
- deterministic decoding → stable output
BCH codes also combine well with bit selection:
effective error rate ↓ → smaller t is enough
Combined flow in VisuKey
- Capture image
- Compute embedding (e.g. 512-dim)
- Binarization → b
- Select stable bits → bstable
- Apply BCH encoding
- Store helper data
- Derive key (hash)
When reading again:
- new r is produced
- error correction reconstructs b
- the same key is produced
Conclusion
Error correction codes are the central piece that turns noisy biometric data into stable cryptographic keys.
BCH codes in particular offer a strong balance of efficiency, correction capability, and implementability.
Combining signal processing, statistical bit selection, and coding theory makes it possible to build reliable, secure authentication from fuzzy real-world measurements—as in VisuKey.
Author: Ruedi von Kryentech
Created: 6 Apr 2026 · Last updated: 6 Apr 2026
Technical content as of the last update.