トランスフォーマーはどう動くか
自己注意、QKV、マルチヘッド、LayerNorm、因果マスクに関する詳細な技術記事
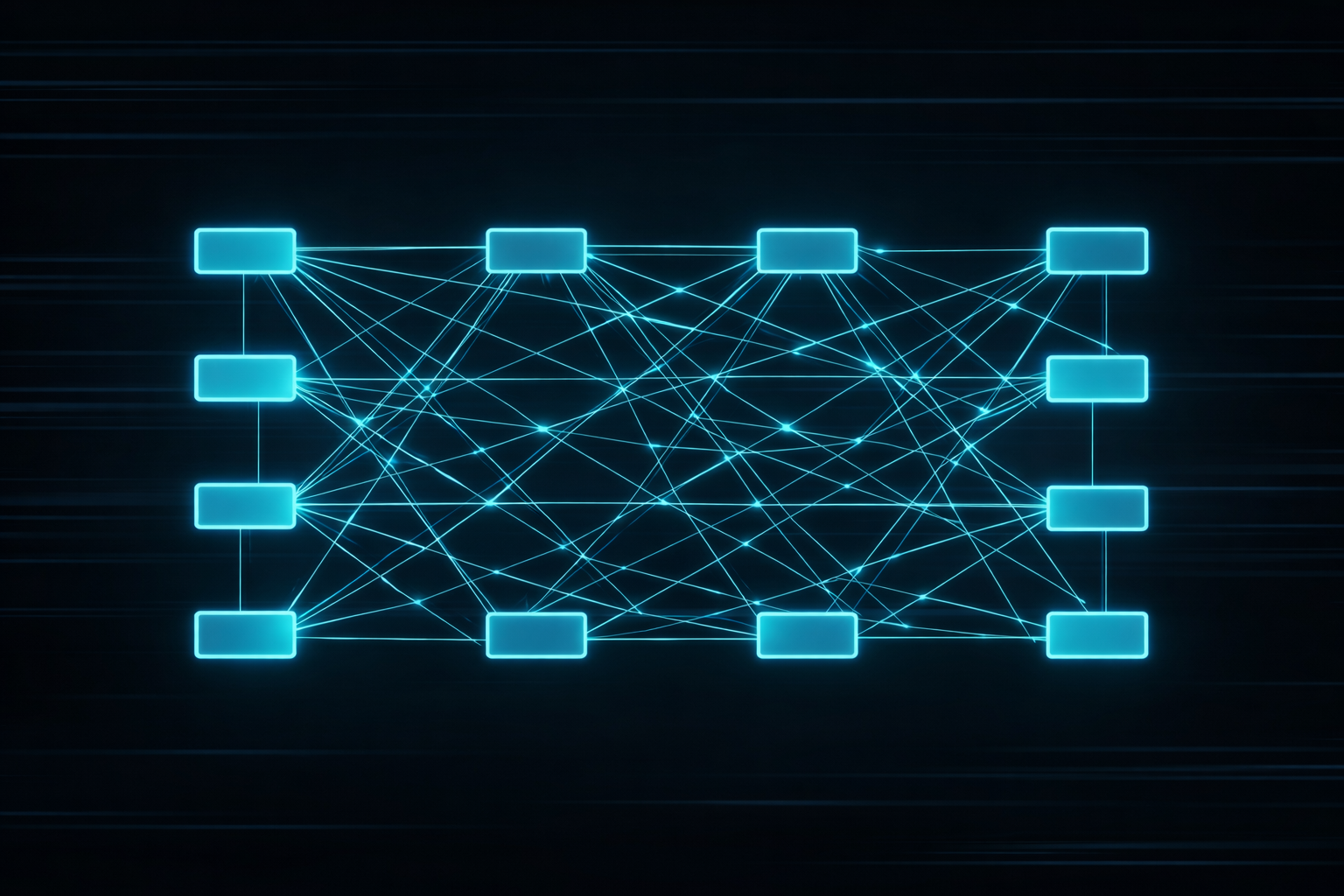
要約: トランスフォーマーは、系列を単に逐次処理するのではなく、自己注意によりすべてのトークン間の大域的文脈関係をモデル化する深いニューラルネットである。
関連記事: ニューラルネットの基礎はLLM背後のニューラルネット。トークン入力表現はニューラルネットにおける埋め込みとベクトル空間。
1. なぜトランスフォーマーか
トランスフォーマー以前、言語処理は主にLSTMやGRUなどの再帰ネットが支配していた。 これらはテキストを厳密に逐次処理する。直感的だが長距離依存には不利である: 遠い位置の情報は多くの時間ステップにわたって運ばれねばならない。
トランスフォーマーは各トークンが他トークンに直接アクセスできるようにすることでこの問題を解く。 大域的関係のモデル化がはるかに容易になる。アーキテクチャはGPU並列計算にも適合する。
\[ y = f_{\theta}(x_1, x_2, \ldots, x_n) \]
重要なのは、関数が近傍や時間だけで局所的に再構成されるのではなく、 すべての位置間の学習可能な重み付けによって大域的に再構成される点である。
2. 古典的ニューラルネットとの違い
「古典的」ニューラルネットは通常、固定の重み行列で層ごとに入力を処理する。 接続パターンは事前に決まる:各層は前層の出力だけを見て、系列全体の文脈を動的には見ない。
トランスフォーマーもニューラルネットだが、自己注意でこの考えを拡張する。 トークン位置間の接続重みは静的に固定されずデータから計算される。これが中心の違いである。
古典例:フィードフォワードネット
1つの線形層と活性化を持つ単純なネットは例えば次を計算する:
\[ y = \sigma(Wx+b) \]
\(x=\begin{bmatrix}1\\2\end{bmatrix}\), \(W=\begin{bmatrix}0.5 & 1.0\\-1.0 & 2.0\end{bmatrix}\), \(b=\begin{bmatrix}0\\1\end{bmatrix}\) とすると、まず
\[ Wx+b= \begin{bmatrix} 0.5\cdot1 + 1.0\cdot2\\ -1.0\cdot1 + 2.0\cdot2 \end{bmatrix} + \begin{bmatrix} 0\\1 \end{bmatrix} = \begin{bmatrix} 2.5\\4 \end{bmatrix} \]
その後活性化を適用する。重要:\(W\)の重みはすべての入力に対して固定である。 ネットは常に同じ接続構造で応答する。
トランスフォーマー例:適応的重み付け
トランスフォーマーは異なる。位置\(i\)では固定行列だけでなく、他位置の重要度を動的に重み付けする:
\[ y_i=\sum_j w_{ij}x_j \]
3つのトークンで重みが \(w_{i1}=0.1\), \(w_{i2}=0.7\), \(w_{i3}=0.2\) なら、 トークン2がトークン1や3よりはるかに強く結果に寄与する。別の文では重みはまったく異なりうる。
これがトランスフォーマーを強力にする:学習された静的パラメータだけでなく、 位置間の文脈依存の適応的結合も用いる。
実務上の違い(一覧)
| 観点 | 古典的NN | トランスフォーマー |
|---|---|---|
| 接続 | 重み\(W\)で固定 | 注意重みで動的 |
| 文脈 | 間接的・局所的 | すべての位置にわたり直接的・大域的 |
| 言語モデル | より限定的 | 長距離依存ではるかに強い |
したがってトランスフォーマーはニューラルネットの対極ではなく、系列と言語のための特に能力の高い ニューラルネットの特化形である。
3. 信号パイプライン全体
言語用トランスフォーマーは概ね次のように記述できる:
テキスト → トークン化 → 埋め込み → 位置情報 → トランスフォーマーブロック → ロジット → 確率
各ブロックは現在の表現をより豊かなものへ写す。最後には次トークン上の分布が立つ。 LLMではこの計算が自己回帰的に繰り返される。
システム論的には状態写像の積層鎖である。各段はベクトル空間上の状態を受け取り、より高い意味密度の新しい状態を生成する。 トランスフォーマーは「言語の小手先」ではなく高次元表現上の構造化された信号処理である。
| 段 | 技術的役割 |
|---|---|
| トークン化 | テキストを離散記号に分割 |
| 埋め込み | トークンを連続ベクトルへ写像 |
| 注意 | 他トークン位置の動的重み付け |
| FFN | 位置ごとの非線形特徴処理 |
| 出力ヘッド | 語彙への射影 |
4. 中核の自己注意
自己注意は各トークンについて次を答える:現在の解釈に他のどの位置が重要か? 機構は動的でデータ駆動である。同じアーキテクチャでも文ごとに依存関係の重み付けは大きく変わりうる。
例:「センサーは飽和しているためエラーを報告した」のように、モデルは「それ」が何を指すかを解決しなければならない。ここで注意が真価を発揮する。
5. Q・K・Vの数学
入力行列\(X\)から3つの射影が作られる:
\[ Q = XW_Q,\qquad K = XW_K,\qquad V = XW_V \]
\(Q\)は各位置のクエリ、\(K\)は他位置が提供する特徴、\(V\)は実際に運ばれる情報である。
注意の計算は:
\[ \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
積\(QK^T\)は類似度を測る。\(\sqrt{d_k}\)での除算は値域を安定化しsoftmaxが速く飽和しないようにする。 結果は値ベクトルの重み付き平均である。
6. マルチヘッド注意
単一の注意ヘッドは文脈のある1つの射影しか捉えられない。したがって機構を並列に複数回実行する:
\[ \mathrm{MultiHead}(X)=\mathrm{Concat}(\mathrm{head}_1,\ldots,\mathrm{head}_h)W_O \]
各ヘッドは異なるパターンを学習しうる:構文、共参照、局所近傍、大域的トピック、位置関係、数値構造など。 より豊かな表現が得られる。
重要:ヘッドは手で専門化されず、訓練から創発する。 一部は近傍検出器のように、他はトピックや文参照や位置関係の大域チャネルのように振る舞う。大規模モデルでは機能的分業が生じる。
7. 言語モデルでのマスク
生成言語モデルではトークンは未来を見てはならない。因果マスクを用いる。 注意スコアで softmax 前に不許可の接続を\(-\infty\)にし、それらの位置が softmax 後に正確に重み0になるようにする。
これにより位置\(t\)は\(\le t\)の位置にのみアクセスできる。制約がなければ訓練中に未来の情報を「写し」うる。
8. フィードフォワード・残差・LayerNorm
注意の後には位置ごとのフィードフォワードネットが続く:
\[ \mathrm{FFN}(x)=W_2\,\sigma(W_1x+b_1)+b_2 \]
この部分ネットは位置ごとの非線形特徴抽出のように働く。現代モデルではGELUやSwiGLUがよく使われる。
残差接続は勾配流を助ける:
\[ y=x+f(x) \]
LayerNormは正規化と学習可能スケールで活性を安定化する:
\[ \mathrm{LayerNorm}(x)=\gamma\cdot\frac{x-\mu}{\sqrt{\sigma^2+\varepsilon}}+\beta \]
\(\gamma\)と\(\beta\)は学習可能パラメータ、\(\varepsilon\)は小さな安定化項である。 これらの部品が合わさり非常に深いネットでも訓練可能である。
工学的には注意部は位置間の適応的結合、FFNは位置内の局所非線形処理に相当する。両方が揃って初めて 大域依存と位置内の特徴精緻化の両方を扱えるモデルになる。
9. 位置情報
注意単体は置換不変である:追加情報がなければ前後の区別がつかない。 したがってトークン表現に位置信号を加えるか回転で埋め込む。
\[ z_i=e_i+p_i \]
一般的な手法は正弦エンコーディング、RoPE、ALiBiなど。システム論的には順序情報を状態空間に明示的に刻むことに相当する。
10. 計算量とスケーリング
標準の注意は系列長\(n\)でおおよそ\(\mathcal{O}(n^2)\)である。すべての位置が他すべてと比較されるからである。 長い文脈では実際のボトルネックになる。
そのためFlashAttention、推論用KVキャッシュ、スパース注意、セグメント化、ハイブリッドアーキテクチャなど多数の最適化がある。 トランスフォーマーはモデルであると同時に高度に最適化された計算系でもある。
実用上これは中核である:理論的に優雅なアーキテクチャもすぐにメモリ帯域・インターコネクト・消費電力の壁にぶつかる。 トランスフォーマー設計は常にアルゴリズムとハードウェアの共同設計でもある。
11. 電気工学の視点
工学的視点: トランスフォーマーは適応的多段信号処理系として自然に解釈できる。
注意はデータ依存フィルタに似る:
\[ y_i=\sum_j w_{ij}x_j \]
古典的FIRフィルタとの違いは係数\(w_{ij}\)が固定でなく信号自体から計算される点である。系は適応的・文脈依存になる。
状態空間・線形射影・正規化による安定化・並列化・メモリ帯域といった概念は信号処理・制御・ハードウェア加速から馴染み深い。
12. まとめ
トランスフォーマーは、大域的・適応的文脈重み付けによって言語をモデル化する深いニューラルネットである。 強みは自己注意、マルチヘッド並列、フィードフォワード処理、残差、LayerNorm、効率的GPU計算の組み合わせから生まれる。
このアーキテクチャが現代LLMの技術的心臓である。ChatGPTのようなシステムを理解するにはトランスフォーマーを理解する必要がある。
数学的基盤を深めるには次にLLM背後のニューラルネットを読む。 主にトークン入力表現に関心があるならニューラルネットにおける埋め込みとベクトル空間が適切な深化である。
著者: Ruedi von Kryentech
作成: 2026年4月14日 · 最終更新: 2026年4月14日
最終更新時点の技術的内容。