ChatGPTの仕組みは?
大規模言語モデル(LLM)—平易な説明と技術的深掘り
ChatGPT、GPT-4、GeminiなどのLLM—次のトークンからトランスフォーマーまで:要点と技術的根拠
1. 大規模言語モデル(LLM)とは
要約: LLMは、文脈からトークン確率を学び、そこからテキストを生成する大きな深層ニューラルネットである。
大規模言語モデル(LLM)は言語の処理と生成に特化した数学的モデルである。 核となるのは人間の意味での「理解」ではなく、テキスト上の確率モデルである。
具体的には、可能な次の語(より正確にはトークン)ごとに、 これまでのテキストに最もよく合う確率を計算する。
LLM = 深層ニューラルネット
重要なのは、LLMはニューラルネットとは別物ではなく、それ自体が 大規模な深層ニューラルネットであること。「深い」とは、入力テキストを段階的に変換する層が多く積み重なっていることを意味する。
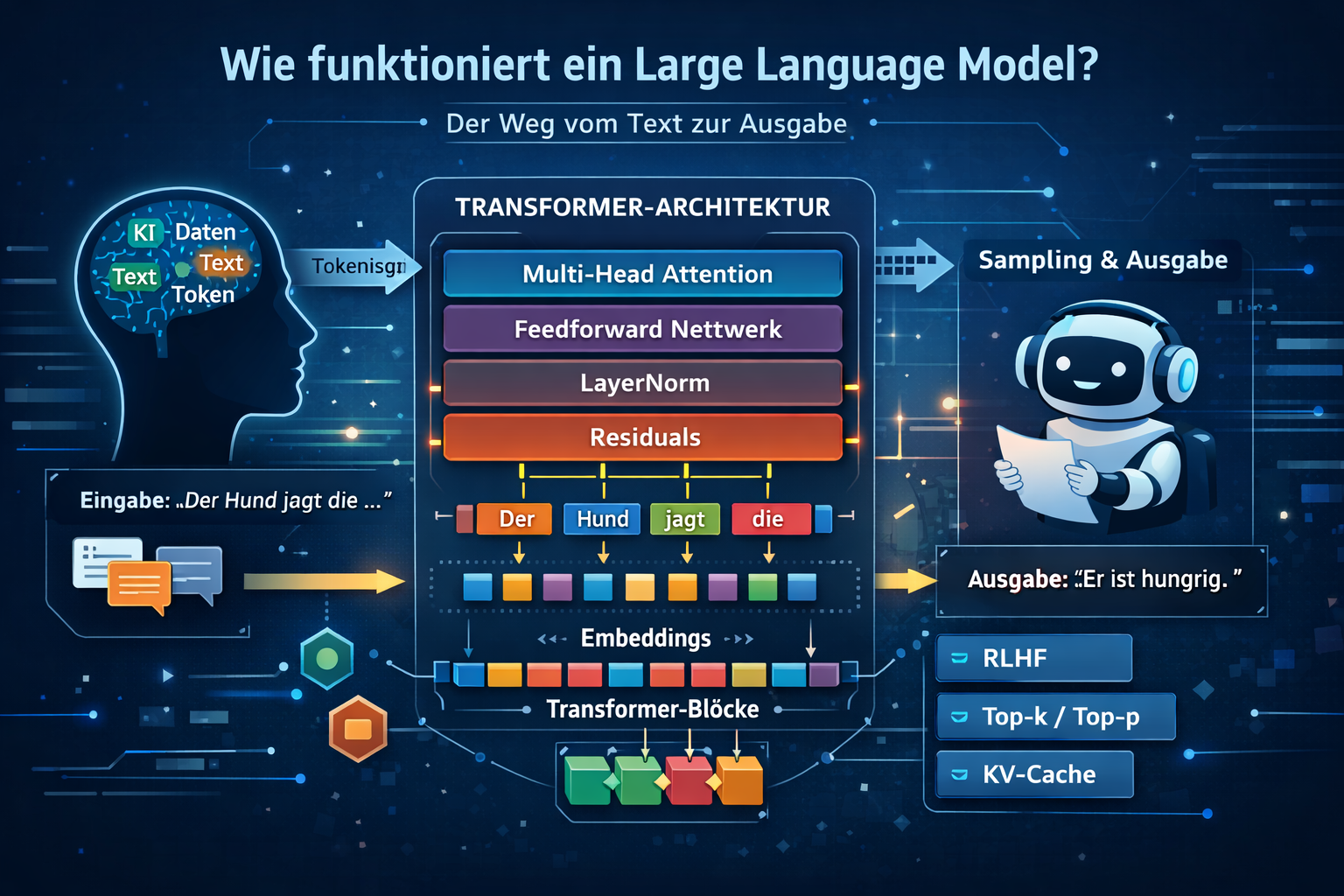
現代のLLMはほぼ常にトランスフォーマーに基づく。 アテンション、フィードフォワード、残差接続、層正規化からなるブロックが繰り返される。 学習中にこれらの重みが調整され、次トークン予測が改善していく。
ここでいう「ニューラルネット」とは
ニューラルネットは本質的に、多くの学習可能パラメータを持つ大きな関数である。 入力信号\(x\)から、多数の重み付き変換を経て出力\(y\)が得られる:
\[ y = f_{\theta}(x) \]
LLMでは入力は画像やセンサ値ではなくトークン列である。 ネットはまずトークンをベクトルに写し、多層を通して処理し、 最終的に次トークン上の確率分布を出力する。
なぜ「ディープラーニング」か
1〜2層だけの小さなネットでは自然言語の複雑さを十分捉えにくい。 多くの層によって階層的特徴が生まれる:
- 下位層は局所パターンや構文、
- 中位層は関係や構造、
- より深い層はより抽象的な意味情報を符号化する。
そのためLLMは明確にディープラーニングの領域に属する。
さらに読む: LLMの背後にあるニューラルネット
言語を数学の問題として
「今日の天気はとても…」のような文は、内部では「意味」としてではなく記号列として扱われる。
モデルの仕事は次に来る確率が最も高いトークンはどれかである。
数学的には確率の連鎖則に基づく:
\[ P(x_1, x_2, ..., x_n) = \prod_{t=1}^{n} P(x_t \mid x_1, ..., x_{t-1}) \]
文全体の確率は、これまでの文脈で条件づけられた各「次トークン」の確率から積み上がる。
自己回帰の原理(ChatGPTの核)
LLMは自己回帰的に動作する。つまり:
- 開始テキスト(プロンプト)を受け取る、
- 次トークンの確率を計算する、
- トークンを選ぶ、
- それを文脈に追加する、
- 繰り返す。
段階的に全文が生成される。
重要: モデルは「全文」を最初から知っているわけではなく、トークンごとに生成する。
トークンとは
トークンはLLMが扱う最小単位である。例:
- 単語全体、
- 部分語(例:「ing」「tion」)、
- 場合によっては文字単位。
例:「unbelievable」は「un」「believ」「able」に分割されうる。
この分割をトークン化といい、モデル効率に直結する。
なぜうまくいくか
巨大なテキストで学習すると、モデルは他にも次を学ぶ:
- 文法と文構造、
- 典型的な語の組み合わせ、
- 論理的つながり、
- 文体のパターン。
「本当の意味」がなくても、驚くほどよく書き、質問に答え、コードを生成し、複雑な話題を説明できる。
要点: LLMは人間のように本当には理解せず、熟考もせず、 古典的な意味での知識も持たない。極めて強力な統計的パターンマッチャである。
2. 中核メカニズム:次トークン予測
核: LLMは確率分布から繰り返し次トークンをサンプルし、自己回帰的にテキストを生成する。
各ステップでモデルは次トークン上の確率分布を計算する。 形式的には:
P(t_{k+1} \mid t_1, t_2, ..., t_k)
選ばれたトークンが文脈に付加され、次のステップへ進む。 この再帰的生成が局所的な決定を一貫したテキストに連なる。
実務での自己回帰フロー
この流れがすべてのLLM応答の運用上の核である。多くの局所ステップが大域的に一貫したテキストになる。
- プロンプトが文脈を与える、
- モデルが次トークンのロジットを計算、
- ソフトマックスで確率化、
- トークンを選択(例:貪欲法やサンプリング)、
- 付加して繰り返し。
応答の長さに応じてこのループは数十〜数百回回る。品質はモデルとサンプリング戦略の両方に依存する。
小さな直感例
文脈:「今日の天気は…」
次トークンに0.42(「晴れ」)、0.25(「寒い」)、0.11(「雨」)のような確率が付くかもしれない。
モデルは全文を最初から「知っている」のではなく、一歩ずつ決める。
うまくいく理由
- 局所予測が連鎖して大域的に一貫したテキストになる、
- これまでの全文脈が各ステップに入る、
- 大規模モデルとデータセットにスケールしやすい。
3. 埋め込みとベクトル空間—意味の表現
核: LLMは語を直接扱うのではなく、高次元空間のベクトルとして処理する。
トークン化の後、各トークンは埋め込み行列でベクトルに写される。 そうして初めてニューラルネットが言語を数学的に扱える。
\[ e_i = E[x_i], \qquad E \in \mathbb{R}^{V \times d} \]
この空間では意味関係が幾何として表れる:似た語は近く、異なる語は遠くなる。 現代のLLMでは表現は文脈依存でもあり、同じ語でも文によって内部ベクトルが変わりうる。
埋め込みはアテンション、文脈モデリング、トランスフォーマー内の以降の処理すべての基盤である。
さらに読む: ニューラルネットにおける埋め込みとベクトル空間
4. トランスフォーマー—LLMの心臓部
この章の位置づけ: トランスフォーマーが現代LLMの性能の主因である。
ChatGPTを含むほぼすべての大規模言語モデルは トランスフォーマーに基づく。2017年に提案され、NLPを変えた。
技術的にはトランスフォーマー自体がニューラルネットである: 多くの学習可能な重み行列、非線形変換、積み重ねた層。 LLMをニューラルネットというとき、通常は 言語用の非常に大きなトランスフォーマーネットを指す。
トランスフォーマーブロックは四つの要素を組み合わせる:
- 大域的文脈結合のためのセルフアテンション、
- 非線形特徴処理のためのフィードフォワード、
- 安定した勾配流のための残差接続、
- 活性化を安定させる層正規化。
アテンションの数学的核は:
\[ \mathrm{Attention}(Q,K,V)=\mathrm{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V \]
各トークンは文脈内のどの位置が重要かを動的に重み付けできる。 マルチヘッドは並列の見方を増やし、因果マスクが言語モデルに「未来」を見させない。
この設計がLLMを強力にする:大域的依存、並列計算、 非常に大きなモデルへの良好なスケーラビリティ。
さらに読む: トランスフォーマーはどう動くか
5. 数値安定性と学習のコツ
要点: LLMの学習は最適化だけでなく数値安定性の問題でもある。
大規模言語モデルの学習は数学の問題であると同時に数値安定性の問題でもある。 特別な工夫がなければ発散、NaN、きれいな収束の失敗が起きやすい。
問題:極端な値の範囲
学習中、非常に大きな値と非常に小さな値が同時に現れる(オーバーフロー/アンダーフロー)。
\[ e^{100} \gg e^{-100} \]
その結果ソフトマックスが不安定になり勾配が使えなくなる。
log-sum-expトリック(中核)
ソフトマックスは数値的に安定した形で計算される:
\[ \mathrm{softmax}(z_i)=\frac{e^{z_i-\max(z)}}{\sum_j e^{z_j-\max(z)}} \]
効果:オーバーフローを避け、相対確率は不変。
ソフトマックスの飽和とアテンションのスケーリング
一つのロジットが支配的(\(z_i \gg z_j\))だと分布はほぼワンホットになり勾配が小さくなる。
アテンションではスケーリングが効く:
\[ \frac{QK^T}{\sqrt{d_k}} \]
内積が大きくなりすぎるのを防ぎ、ソフトマックスを学習可能な範囲に保つ。
混合精度学習
現代のLLMは速度のためFP16/BF16、重要な安定ステップのためFP32を使うことが多い。
FP16はダイナミックレンジが狭いためロススケーリングが一般的:
\[ g' = g \cdot S,\qquad g=\frac{g'}{S} \]
アンダーフローを減らし学習を安定させる。
勾配クリッピング
勾配爆発(\(\lVert g\rVert \to \infty\))では更新が不安定。クリッピングでノルムを制限:
\[ g=\frac{g}{\lVert g\rVert}\cdot c \]
典型的には\(c=1.0\)。
層正規化と残差
LayerNormはブロック内の活性化を安定させる:
\[ \mathrm{LayerNorm}(x)=\frac{x-\mu}{\sigma} \]
残差は勾配流を改善:
\[ y=x+f(x) \]
両方とも深いトランスフォーマーに不可欠。
活性化関数とトレードオフ
GELUやSwiGLUは単純な代替より滑らかな勾配と収束をもたらしやすい。
活性チェックポイントやZeRO/FSDPはメモリを節約するが計算とデバッグは重くなる。
実務でのNaN
典型原因:学習率過大、初期化不良、ソフトマックスのオーバーフロー、FP16の影響。
実践:勾配ノルム確認、損失監視、活性/ロジット範囲のログ。
実務でのPyTorch—数値的に安定したLLMコード
多くの現代LLMはPyTorchなどで実装され、 安定化機構が組み込まれている。
安定な交差エントロピー
手計算のsoftmax+logの代わりに:
import torch.nn.functional as F
loss = F.cross_entropy(logits, targets)
内部ではlog_softmax(log-sum-exp)と負の対数尤度など安定な手順が使われる。
より安定で通常高速(融合カーネル)。
AMPによる混合精度
from torch.cuda.amp import autocast, GradScaler
scaler = GradScaler()
with autocast():
logits = model(x)
loss = F.cross_entropy(logits, y)
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()FP16/BF16とFP32が自動で組み合わされ、安定勾配のためのロススケーリングも含まれる。
実行時間とメモリを大きく削り、素朴なFP16より数値安定性を保てる。
フレームワーク内の勾配クリッピング
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)勾配爆発を抑え不安定な更新を防ぐ。
深いネットや大バッチでは重要な安全装置。クリッピングなしでは外れ値が最適化全体を壊しうる。
典型的なベストプラクティス
本番に近い学習パイプラインでは、最適化・安定性・効率を同時に満たす組み合わせがよく使われる。
- 最適化器はAdamW、
- AMPを有効化、
- 勾配クリッピングをオン、
- 手書きsoftmaxではなく
F.cross_entropy。
多くのLLM学習スタックで業界標準に近い。
PyTorchのまとめ
PyTorchは複雑さを数行に隠すが、 数値安定性の理解は失敗のデバッグ、学習調整、大規模モデルの安定運用に不可欠。
この章のまとめ
数値安定性は細部ではなく、この規模で学習可能なLLMの前提である。 安定したソフトマックス、スケーリング、クリッピング、層正規化、残差の組み合わせが堅牢な学習を可能にする。
6. 分散学習とシステム設計
要点: この規模のモデルは分散学習と効率的なシステム設計がなければ実現しにくい。
現代の大規模言語モデルは単一マシンでは学習できない。 数十億パラメータ、巨大なデータ、パラメータ・勾配・最適化状態のための非常に大きなメモリがそれを不可能にする。
核:並列化
負荷を分散するため学習は多くのGPUに分割される。主な戦略は:
この分割がなければ実行時間とメモリはすぐに現実的でなくなる。 並列化は任意の最適化ではなく、現代LLM開発の前提である。
データ並列
各GPUは完全なモデルコピーを持ち、異なるバッチを処理する。
各ステップ後に勾配を平均:
\[ g=\frac{1}{N}\sum_{i=1}^{N} g_i \]
単純で広く使われるが、モデル全体が1枚のGPUに収まる場合に限る。
モデル並列
モデル自体を分割する。例:
- テンソル並列(層内分割)、
- パイプライン並列(層をまたぐ分割)。
超大規模モデルに必要だが通信コストが増える。
メモリ最適化(ZeRO / FSDP)
完全レプリカの代わりに、パラメータ・勾配・最適化状態をGPU間でシャードする。 メモリを大きく削り、極めて大きなモデルを可能にする。
中心のボトルネック:通信
大規模クラスタでは生の計算力ではなくGPU間のデータ転送が限界になりがちである。 効率的な同期とネットワークトポロジーが全体効率を決める。
実運用の学習システム
現代のLLMは数百〜数千GPU、高速ネットワーク、分散ストレージのクラスタで動く。 学習はソフトウェア・ハードウェア・ネットワークの共同作業になる。
GPU市場への影響
高い計算需要は経済に直結する:
- AI学習による強い需要、
- 製造キャパの制約、
- コンシューマよりデータセンター志向。
GPU価格の上昇、納期の長期化、AI開発の参入障壁の高さなどが挙げられる。
この章のまとめ
分散学習は現代LLMの前提である。 LLM開発は数学だけでなくインフラ・スケール・経済の問題でもあることがはっきりする。
7. 大規模言語モデルの学習—数学と最適化
核: 学習とは予測誤差を最小化し、実テキストがモデル下でより起こりやすくなるようパラメータを反復更新することである。
大規模言語モデルは次トークンの分布をできるだけ正確に予測するよう学習される。 形式的には次を近似する:
\[ P(x_t \mid x_1, x_2, ..., x_{t-1}) \]
目的:最尤推定
学習には最尤推定(MLE)を用いる。系列 \(x_1, ..., x_n\) に対し次を最大化:
\[ \mathcal{L} = \sum_{t=1}^{n} \log P_{\theta}(x_t \mid x_1, ..., x_{t-1}) \]
直感:実テキストはモデル下で高い確率を持つべきである。 良い予測は目的を上げ、悪い予測は下げる。
交差エントロピー損失(実装形)
実装では通常交差エントロピーを最小化:
\[ \mathcal{L} = -\sum_{i} y_i \log p_i \]
- \(y_i\):正解トークン(one-hot)、
- \(p_i\):モデルが予測した確率。
完璧な予測は非常に小さい損失、誤りは大きい損失—負の対数尤度である。
パープレキシティ—モデルの良さ
言語モデルの重要な指標がパープレキシティ:
\[ \mathrm{Perplexity} = \exp\left(\frac{1}{n}\sum \mathrm{Loss}\right) \]
- 値10:おおよそ約10トークン間で不確実、
- 値2:非常に良い、
- 値1:理論上の完璧。
パープレキシティが低いほどデータ分布によりよく適合する。
トランスフォーマーを通した誤差逆伝播
各学習ステップは同じパターンに従う:
- 順伝播(予測)、
- 損失計算、
- 勾配計算、
- パラメータ更新。
この列が順モデル・損失・最適化器を一つの学習過程に結ぶ。 誤差逆伝播がなければ数十億パラメータを狙って改善するのは現実的でない。
勾配の重要な性質
softmax + 交差エントロピーでは:
\[ \frac{\partial \mathcal{L}}{\partial z_i} = p_i - y_i \]
この形は計算効率が良く数値的にも安定—ほぼすべてのLLMでこの組が使われる理由の一つ。
Adam / AdamW による最適化
実務ではAdamまたはAdamWが典型。Adamは勾配の平均と分散の移動推定を用いる:
\[ m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t \]
\[ v_t = \beta_2 v_{t-1} + (1-\beta_2) g_t^2 \]
\[ \theta_t = \theta_{t-1} - \eta \frac{m_t}{\sqrt{v_t} + \epsilon} \]
AdamWは重み減衰を加え、大規模モデルでの正則化を改善する。
学習の安定性(重要)
大規模モデルの信頼できる学習には複数の安定化機構が連携して働く必要がある。 それぞれが最適化における異なる失敗モードに対処する。
- 勾配クリッピング: \(\lVert g \rVert \le c\)、勾配爆発を防ぐ。
- 学習率スケジュール: ウォームアップの後、しばしばコサイン減衰。
- 混合精度: 速度のためFP16/BF16、重要な安定性のためFP32。
これらの組み合わせだけが長期学習を再現可能かつ安定にする。 実務では安定性は生のモデルサイズと同じくらい重要なことが多い。
学習が高価な理由
計算量はおおよそパラメータ数とデータ量に比例:
\[ \mathrm{Compute} \propto N \cdot D \]
数十億パラメータと巨大なトークン数は極めて高いFLOPコストを生む。
大規模モデルでのメモリ圧力
パラメータ・勾配・最適化状態をすべて保持する必要がある。Adamでは生のモデルサイズの約3〜4倍になることが多い。
典型的な緩和策:
- ZeRO(シャーディング)、
- FSDP、
- 活性チェックポイント。
学習パイプライン(現実的)
実際の学習ループには次が含まれる:
- トークン化(BPE / バイトレベル)、
- バッチ構築、
- トランスフォーマー順伝播、
- 損失計算、
- 誤差逆伝播、
- 最適化ステップ。
このサイクルを多くのステップ繰り返す。
この章のまとめ
LLMの学習の核は確率の学習・誤差の最小化・パラメータの反復最適化である。 実務では極端なデータ量、複雑な最適化、巨大なハードウェアコストが加わる。
電気工学との接続—信号処理とシステム
大規模言語モデルは主に計算機科学から来るが、電気工学—特に信号処理とシステム理論—とも強く結びつく。 多くの基本アイデアは電気技術者にはすでに馴染み深い。
ニューラルネットを信号処理系として
LLMは多段系として見られる:
\[ y=f(x) \]
デジタルフィルタ、伝達関数、非線形系と並行する:各層が入力信号(トークン列ベクトル)を出力信号へ写像する。
注意機構を動的フィルタとして
自己注意は次のように書ける:
\[ y_i=\sum_j w_{ij}x_j \]
比較:FIRフィルタは係数が固定、注意は現在の信号に依存する適応係数を持つ。 古典的系はしばしば静的、LLMは動的で文脈依存である。
周波数と情報の見方
明示的なフーリエ変換がなくても類似が現れる: 浅い層は局所パターン、深い層はより抽象的な情報を学びがち—カスケードフィルタと特徴抽出に似る。
この見方は古典的信号処理とLLMの橋渡しになる。 モデルは言語を扱うが、構造は馴染みの多段処理チェーンを思わせる。
最適化をシステム同定として
学習はシステム同定として読める:
\[ \theta^*=\arg\min_{\theta} L(\theta) \]
目的は測定(ここではテキスト)から未知の系を最良近似することである。
ハードウェアの観点
GPUは大規模並列行列演算を実行する—DSPやFPGA加速と概念的に近い: 並列化、メモリ帯域、遅延調整が共通の中心テーマである。
違いは主に規模とソフトウェアスタックであり、効率的数値処理の原理ではない。 現代AIも古典工学に大きく依存している。
電気技術者へのメッセージ
LLMは異質な概念ではなく、信号処理、線形系、非線形最適化、高並列ハードウェアを組み合わせたものである。 大きな違いは主に規模と適応性にある。
8. スケーリング則—大きいモデルがよくなる理由
現代AI研究の主な発見の一つは、言語モデルの性能が安定した数学的パターンに従うことである。 これらの関係をスケーリング則と呼ぶ。
核:すべてを増やすと性能が上がる
LLMは典型的に次の三量が増えると改善する:
- パラメータ数 \(N\)、
- 学習データ \(D\)、
- 計算予算 \(C\)。
改善は無作為な曲線ではなく、頑健なべき乗則に従う。
数学的則(べき乗則)
損失はモデルサイズに対しておおよそ次のようにスケールしうる:
\[ L(N) \propto N^{-\alpha} \]
より一般的にはしばしば次のようにモデル化:
\[ L(N,D,C) \approx aN^{-\alpha} + bD^{-\beta} + cC^{-\gamma} \]
意味:パラメータ・データ・計算を増やすと損失は測定可能に改善するが、収穫逓減がある。
対数–対数挙動と予測
対数–対数プロットではこれらの関係はしばしばほぼ線形になる。 将来のモデルサイズに対するスケーリング効果を比較的確実に見積もれる。
計算の最適性(チンチラの示唆)
中心的な発見は、モデルサイズだけがすべてではないということである。固定の計算予算の下では、 パラメータとデータのバランスが合うべきである。単純化すると:
\[ N \propto D \]
多くの先行モデルは学習不足だった。実務では、データをはるかに多く与えた中規模モデルが、 データ不足で学習した極大モデルに勝つことがある。
計算予算は硬い制約
学習コストはおおよそ次に比例:
\[ C \propto N \cdot D \]
パラメータとデータをそれぞれ2倍にすると計算はおおよそ4倍に近づく。
創発的能力
ある規模の閾値を超えると、論理推論・翻訳・コーディングなど、突然新しい能力が現れることがある。 これを創発的能力と呼ぶ。
原因は完全には解明されていない。複雑性の閾値、より頑健な汎化、豊かな内部表現などが議論される。
重要な注意
強いスケーリングが人間のような理解を生むわけではない。モデルは意識や意図のない統計的フィッティング機械のままである。
大きいモデルは適合が細かく頑健なため「できる」ように感じられることが多いが、根底は依然として確率モデリングである。
スケーリングの限界
スケーリングはしばしば性能を着実に上げるが、無限には続けられない。ある点を超えると コスト・エネルギー・データ品質が実現可能性を支配する。
- コストとエネルギーが急増する、
- 高品質データが希少になる、
- 極端な規模での学習は安定維持が難しくなる。
そのため今日ではより効率的なアーキテクチャと学習レシピにも焦点が向く。
この章のまとめ
スケーリング則は、LLMの改善が無作為ではなく再現可能な数学的規則に従うことを示す。 パラメータとデータを増やすことは有効だが、正しい比率でのみである。
9. 推論とサンプリング—LLMがテキストを生成する仕組み
実務上の注意: 同じモデルでもサンプリング次第で印象は大きく変わる—安定・事実寄りから創造的でリスクのある出力まで。
学習後、LLMは推論時にプロンプトから新しいテキストを生成する。 生成は自己回帰的に、トークンごとに進む。
\[ x_{t+1} \sim P(x_{t+1} \mid x_1, ..., x_t) \]
典型的な1ステップの流れ:
- プロンプト/文脈が与えられる、
- モデルがロジットを計算、
- softmaxで確率化、
- サンプリングでトークンを選ぶ、
- トークンを連結し繰り返す。
ロジットから確率へ
生の出力はロジット \(z_i\)。softmaxで確率に変換:
\[ p_i = \frac{e^{z_i}}{\sum_j e^{z_j}} \]
大きいロジットは高確率、小さいものはほぼゼロ。実装ではlog-sum-expで安定化する。
サンプリング戦略
常に最上位トークンを取る必要はない。戦略で文体・多様性・安定性が変わる。
同じ分布でもここでユーザー体験は大きく分岐する。サンプリングは細部の実装ではなく、 実用的なモデル制御の中核である。
貪欲サンプリング
\[ x = \arg\max_i p_i \]
利点:決定的で速い。欠点:しばしば反復的で不自然。
厳密に再現したい出力や事実寄りには向く。自然な対話には硬すぎることが多い。
温度
\[ p_i = \frac{e^{z_i/T}}{\sum_j e^{z_j/T}} \]
- \(T<1\):保守的で焦点の絞られた出力、
- \(T>1\):創造的だがリスクも増える。
温度は文体と多様性を調整する主要な実務レバーの一つ。
\(T\)のわずかな変更で回答の性格が大きく変わるため、用途に合わせて調整される。
Top-k サンプリング
上位 \(k\) トークンのみ候補に残し、それ以外は捨てる。その候補からサンプルする。
極めて低確率でしばしば無意味なトークンを切り捨てる。
Top-p(核サンプリング)
累積確率が少なくとも \(p\) に達する最小のトークン集合を動的に選ぶ:
\[ \sum_i p_i \ge p \]
例:\(p=0.9\) はおおよそ上位90%の確率質量。文脈に適応し実務で広く使われる。
KVキャッシュ—推論が速くなる理由
キャッシュがなければ新トークンごとに注意を全再計算する。KVキャッシュは過去トークンのキー/値状態を保持する。
新トークンあたりの追加コストが急減する(毎回全文脈をやり直さない)。
KVキャッシュのメモリトレードオフ
キャッシュは文脈長・モデル幅・層数に比例して増える:
\[ \mathrm{Memory} \propto L \cdot d \cdot \mathrm{Layers} \]
長い文脈は品質を上げやすいがメモリを大きく要する。
ニューラルテキスト劣化
サンプリング設定が悪いと反復的で不自然なテキストになる。 戦略・温度・top-p/top-kは知覚される回答品質を強く形作る。
決定性と創造性
再現性の最大化と多様性の最大化は常にトレードオフである。 精度・自然さ・創造的幅のどれを重視するかで最適設定は変わる。
| 設定 | 挙動 |
|---|---|
| 低温+貪欲 | 安定だが単調になりがち |
| 中温+top-p | 自然でバランスが良い |
| 高温 | 創造的だが誤りも増えやすい |
本番系は中間帯を選ぶことが多い—十分安定しつつ自然さも保つ。
回答がばらつく理由
同じプロンプトでも、サンプリングの乱数、浮動小数点の差、並列実行により回答は変わりうる。
そのばらつきが自動的に信頼性の欠如を意味するわけではない—多くはデコーディング方式の帰結である。 厳密な再現性にはサンプリングと実行環境の制御が要る。
この章のまとめ
LLMのテキスト生成は確率分布上の反復サンプリングである。 softmaxが分布を与え、サンプリングが選択し、KVキャッシュが高速化し、 ハイパーパラメータが文体と創造性を決める。
10. RLHFとアライメント—LLMが「人間らしく」感じる理由
要点: RLHFが主に変えるのは振る舞い(有用性・安全性・文体)であり、核の数学的機構ではない。
次トークン予測だけで学習した素の言語モデルは流暢に書けるが、アライメントなしでは散漫・不親切・リスクのある回答を出しうる。 そのため人間フィードバックからの強化学習(RLHF)などのアライメント手法で調整する。
アライメントの目的
最もありそうなテキストだけでなく、有用でできるだけ正しく、人にとって安全な回答を出すことが望ましい。
アライメントは最適化の焦点を「ありそう」から「有用で許容できる」へずらす。 よく整えられたモデルが日々の利用でずっと役に立つように感じられるのはこのためである。
RLHFパイプライン(技術)
典型的には三段階:
- 教師ありファインチューニング(SFT): 人間が高品質な回答例を与える。
- 報酬モデル: 人が回答を比較(AがBより良い)し、それからスコアリングモデルを学習。
- 強化学習(例:PPO): 言語モデルを高報酬になるよう最適化。
このパイプラインはデモンストレーション学習・嗜好学習・行動最適化を分離し、 人間の期待に段階的に合わせられる。
1)教師ありファインチューニング(SFT)
整備した質問–回答ペアでモデルは次を学習:
\[ P_{\theta}(\text{answer} \mid \text{question}) \]
依然として教師あり学習だが、広い事前学習より高品質なデータである。
2)報酬モデル
嗜好データ \((x, y_{\text{better}}, y_{\text{worse}})\) からスコアリングモデルを学習:
\[ R_{\phi}(x,y) \]
人間の観点で回答がどれだけ良いかを推定する。
3)PPOによる強化学習
言語モデルは期待報酬を高めるよう最適化:
\[ \max_{\theta} \ \mathbb{E}[R_{\phi}(x,y)] \]
PPO(近接方策最適化)は更新を抑え、学習を安定させる。
\[ L_{\mathrm{PPO}} = \mathbb{E}\left[\min\left(r(\theta)A,\ \mathrm{clip}(r(\theta),1-\epsilon,1+\epsilon)A\right)\right] \]
核:方策を大きく飛ばさずに改善する。
モデルがここから学ぶこと
RLHFは主に文体・構造・安全な振る舞いに効く。基礎知識を作り直すわけではなく、 優先順位と提示の仕方が変わる。
- より丁寧で構造のはっきりした回答、
- 不確実性の伝え方の改善、
- リスクのある内容をより避ける。
RLHFは振る舞いを操り、アーキテクチャそのものではない。
重要な注意
RLHFの後も意識や真の理解は生じない。モデルは依然として統計的に最適化しており、 目標が人間の嗜好によりよく反映されただけである。
アライメントのトレードオフ
アライメントは使いやすさを上げるがタダではない。安全や嗜好の層を足すたびに モデルの自由度も変わる。
利点:
- より使える回答、
- 安全性の向上、
- 滑らかな対話。
欠点:
- フィードバックデータ由来のバイアス、
- 過剰アライメント(慎重すぎる)、
- 創造の自由度が下がることがある。
実務では開放性・安全性・有用性の妥協が常に必要であり、 現代アシスタント設計で最も難しい問いの一つである。
RLHFを超えた安全層
RLHFに加え、しばしば次も使う:
- コンテンツフィルタ、
- モデレーション、
- システム方針。
これらは生成の前・中・後に作用し、単一のゲートではなく層状の安全になる。
評価:品質の測り方
パープレキシティだけでは足りない。実務では次を組み合わせる:
- 人間評価、
- ドメインベンチマーク、
- 頑健性・安全性テスト。
アシスタントの品質は多次元である。
小さいモデルの方が良く感じることがある理由
小さくてもよくアライメントされたモデルは、大きいが未調整のモデルより 利用者には良く感じられることがある—振る舞いと回答スタイルが強く調整されているため。
知覚される品質は知識やパラメータ数だけで決まらない。 多くのアプリでは対話品質が生のモデルサイズと少なくとも同等に重要である。
この章のまとめ
RLHFは現代AIが有用で構造化され、やや「人間らしく」感じられる主な理由の一つである。 トランスフォーマーの核は変えない—行動目的を変える。
11. 限界と技術的リスク
- ハルシネーション: もっともらしいが事実と異なる記述。
- バイアス: 学習データの歪みを取り込む。
- 文脈の上限: 1リクエストあたり扱えるトークン数に限界がある。
- コスト: 学習と推論に大きな計算資源が要る。
12. まとめ
大規模言語モデルは言語を理解し、思考し、論理的に推論する知的システムのように見える。 核は明確な原理に立つ:言語上の確率をモデル化する。
数学的最適化(損失最小化)、スケール可能なアーキテクチャ(トランスフォーマー)、 巨大データセット、狙ったファインチューニング(RLHF)を組み合わせると、 言語を極めて忠実に模倣する系ができる。
本当の「魔法」
LLMの強みは真の理解ではなく、高次元ベクトル空間、複雑なパターンマッチング、 規模に伴う創発的能力にある。思考のように感じるものは、結局は統計構造への非常によい適合である。
見かけの魔法は、既知の技術要素が協働する結果であり、 規模・学習データ・最適化の深さが主に印象を決める。
工学と現実
現代のLLMは同時に:
- 深層ニューラルネット、
- 数十億パラメータの最適化問題、
- 分散高性能計算システム、
- 人間によってアライメントされた道具、
である。理論・数学・工学が高い水準で結ばれている。
展望
現在の流れは次を指し示す:
- より効率的なモデル(同能力で計算を減らす)、
- より長い文脈ウィンドウ、
- より良いマルチモダリティ(テキスト・画像・音声)、
- より強いアライメントと安全性。
根底の原理は変わらない。
締めくくり
大規模言語モデルは思考する存在ではなく、極めて能力の高い道具である。 単純な核のアイデアと複雑な実装の組み合わせが、LLMをこの時代を象徴する技術の一つにしている。
著者: Kryentech の Ruedi
作成: 2026年4月14日 · 最終更新: 2026年4月14日
技術的内容は最終更新時点のものです。